Amazon a ouvert la voie de l’Infrastructure-as-a-service (IaaS) avec son offre Amazon Web Services. Que ce soit Netflix, la NASA ou la marine américaine, tous ont choisi Amazon en tant que back-end. AWS S3 est le service de stockage d’AWS, et la cause de plusieurs fuites de données majeures.
Cet article de blog présente les fondamentaux d’AWS S3 et explique comment sécuriser le système afin de prévenir les incidents de cybersécurité.
Qu’est-ce qu’AWS S3 (Simple Storage Service) ?
AWS S3 est l’un des services fondamentaux de l’infrastructure AWS. D’un point de vue conceptuel, c’est l’équivalent d’un serveur de fichiers d’une capacité infinie, situé sur un site distant ou un serveur FTP.
Amazon S3 stocke les données chargées sous forme d’objets dans des « compartiments ». Plutôt que d’utiliser des serveurs de fichiers, la structure de S3 s’organise en compartiments et en objets.
Un objet peut être un fichier DOC ou vidéo, accompagné de métadonnées qui le décrivent. Les compartiments sont les conteneurs qui accueillent un objet. Les administrateurs peuvent configurer et gérer l’accès à chaque compartiment (c’est-à-dire déterminer et contrôler qui peut créer, supprimer et lister les éléments du compartiment), consulter les journaux d’accès au compartiment et aux objets qu’il contient et choisir la zone géographique dans laquelle Amazon S3 conserve le compartiment et son contenu.
Types de stockage d’une configuration Amazon S3
Amazon a mis au point Amazon S3 comme une solution durable et flexible qui offre de nombreuses possibilités de stockage pour répondre aux besoins spécifiques de ses clients, à savoir :
- Standard : pour stocker des données sensibles aux performances avec un délai de récupération de l’ordre de la milliseconde.
- Standard – Accès peu fréquent : pour enregistrer des données consultées de manière peu fréquente.
- Unizone – Accès peu fréquent : pour les objets utilisés rarement et nécessitant une moindre durabilité. Cette option permet de réduire les coûts par rapport aux autres formes de stockage.
- Amazon Glacier : Amazon Glacier est utilisé pour le stockage des données archivées.
Dans quel cas utiliser AWS S3 ?
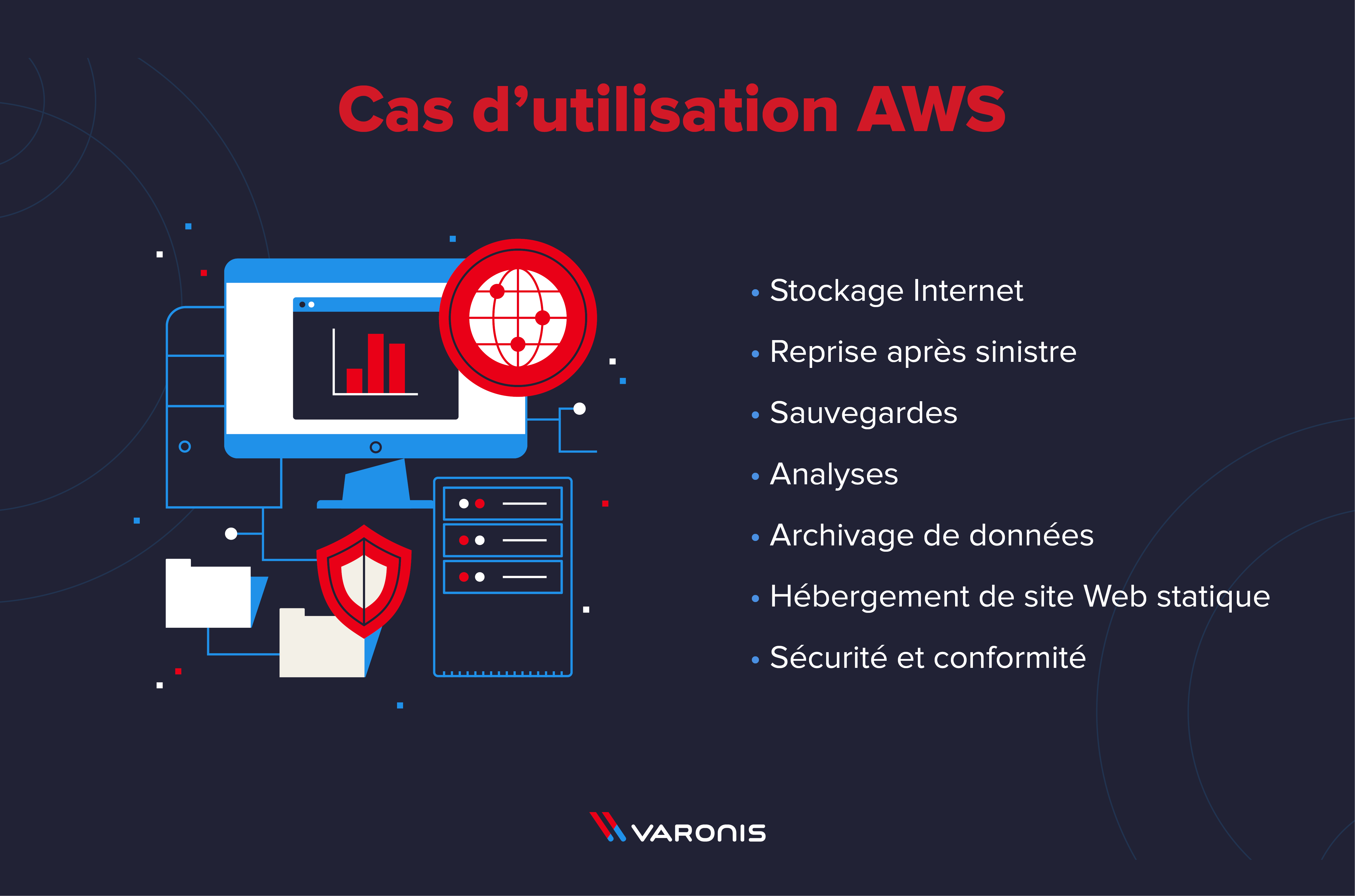
Il existe une diversité de cas d’usage pour AWS S3 ; en voici quelques-uns.
Stockage Internet
Amazon S3 convient parfaitement au stockage d’images applicatives et de vidéos nécessitant des performances de rendu élevées. Tous les services AWS (y compris Amazon Prime et Amazon.com), mais aussi Netflix et Airbnb, utilisent Amazon S3 à cette fin.
Reprise après incident et sauvegarde
Le service Amazon S3 est parfait pour stocker et archiver des données très sensibles ou des sauvegardes. Le stockage, qui est automatiquement distribué entre plusieurs régions, offre les niveaux les plus élevés de disponibilité et de durabilité. Vous pouvez faciliter la restauration des fichiers ou des versions antérieures grâce au contrôle de version Amazon S3. La perte d’informations est très peu probable avec Amazon S3 si vous privilégiez des objectifs de point de récupération (RPO) et de délai de récupération (RTO) peu élevés.
Analytique
Amazon S3 offre des fonctionnalités avancées d’interrogation sur site pour effectuer des analyses très efficaces des données S3. Il est ainsi inutile de déplacer les données et de prévoir un stockage spécifique, puisque S3 facilite la plupart des services faisant intervenir des tiers.
Archivage des données
Les utilisateurs peuvent stocker leurs données et les transférer d’Amazon S3 vers Amazon Glacier, une solution d’archivage conforme, durable et peu coûteuse. Il est également possible d’automatiser les données archivées avec une stratégie de cycle de vie qui favorise la gestion des données avec un minimum d’effort.
Hébergement de site Web statique
Amazon S3 stocke différents types d’objets statiques. L’hébergement de sites Web statiques est donc un cas d’usage important. De plus en plus d’applications Web étant des pages uniques ou des sites statiques (Angular, ReactJS, etc.), le recours à un serveur Web est coûteux. S3 fournit une fonctionnalité d’hébergement de sites Web statiques qui permet d’utiliser votre nom de domaine sans engager de frais d’hébergement importants.
Sécurité et conformité
Amazon S3 offre plusieurs fonctions de chiffrement et de conformité pour les normes PCI-DSS, HIPAA/HITECH, FedRAMP, FISMA, etc. Grâce à elles, les clients peuvent remplir les critères de conformité imposés partout dans le monde par les organismes de réglementation… Et il est plus facile de restreindre l’accès aux données sensibles avec des stratégies de compartiments.
Comment utiliser AWS S3 ?
Toutes les données S3 résident dans des compartiments mondiaux spéciaux, avec plusieurs répertoires et sous-dossiers. Choisissez une région lors de la création du compartiment pour optimiser la latence et réduire les coûts d’accès aux données. Pour configurer Amazon S3, procédez comme suit :
- Créez un compartiment S3
- Chargez des fichiers dans le compartiment S3 créé
- Accédez aux données du compartiment
Créez un compartiment S3
Vous trouverez ci-dessous des instructions et des captures d’écran pour créer un compartiment S3.
1. Connectez-vous
Ouvrez un compte pour la console de gestion AWS. Une fois connecté, vous arrivez sur l’écran ci-dessous.
2. Recherchez « S3 »
Saisissez « S3 » dans la barre de recherche et validez.
Le tableau de bord AWS S3 doit se présenter comme suit.
3. Cliquez sur « Create bucket » (Créer un compartiment)
Cliquez sur le bouton « Create bucket » pour créer un compartiment S3. Une fois que vous avez cliqué, vous accédez à cet écran :
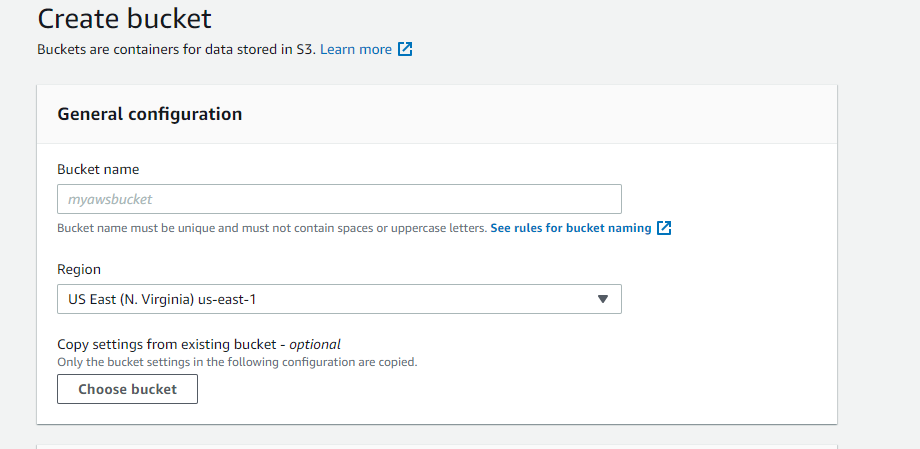
4. Nommez le compartiment
Saisissez le nom de votre compartiment.
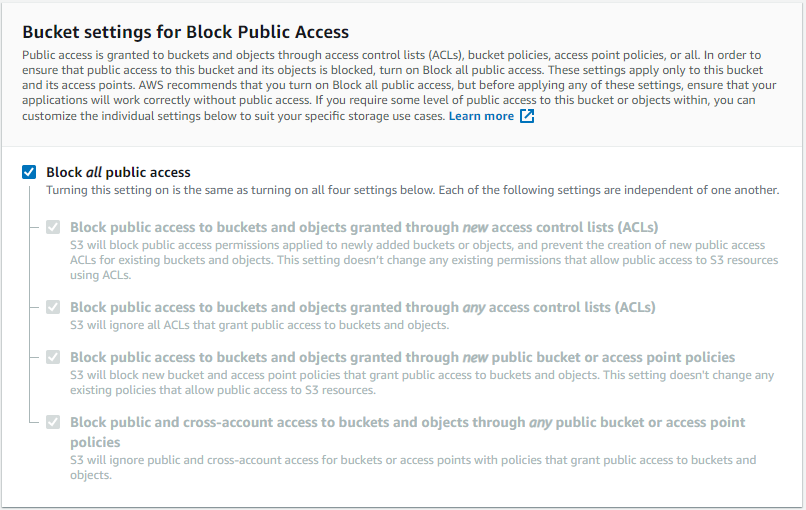
Il existe plusieurs manières de configurer les autorisations de votre compartiment S3. L’autorisation par défaut est « Private » (Privé), mais il est possible de la modifier via la console de gestion AWS ou une stratégie de compartiment. En termes de sécurité, il est recommandé d’être sélectif lorsque vous accordez l’accès aux compartiments S3 que vous créez. Ajoutez uniquement les autorisations nécessaires et évitez d’ouvrir le compartiment au public.
5. Configurez les options (facultatif)
Vous pouvez choisir les fonctions à activer pour un compartiment donné, par exemple :
- Balises : vous pouvez associer une clé et un nom à votre compartiment afin de faciliter la recherche des ressources.
- Gestion des versions : gardez une trace de toutes les versions d’un fichier afin de le récupérer facilement en cas de suppression accidentelle.
- Journalisation au niveau objet (Paramètres avancés) : activez cette fonction si vous voulez consigner toutes les opérations effectuées sur les éléments de votre compartiment.
- Chiffrement par défaut : par défaut, AWS chiffre les fichiers selon la norme AES 256 avec génération de clés, mais vous pouvez utiliser votre propre clé de chiffrement gérée.
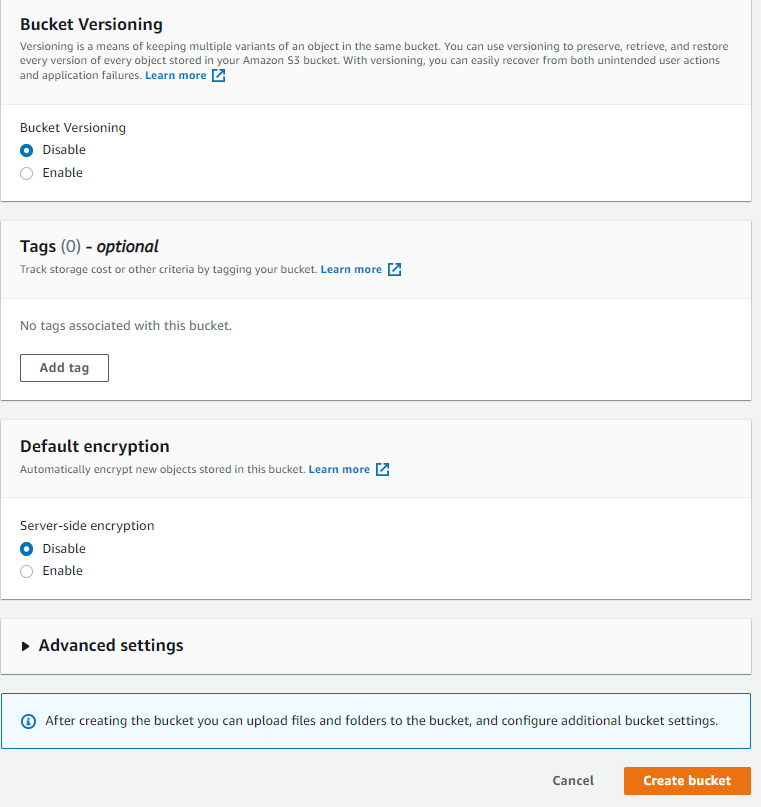
6. Créez le compartiment
Pour finir, cliquez sur « Create bucket » (Créer un compartiment).

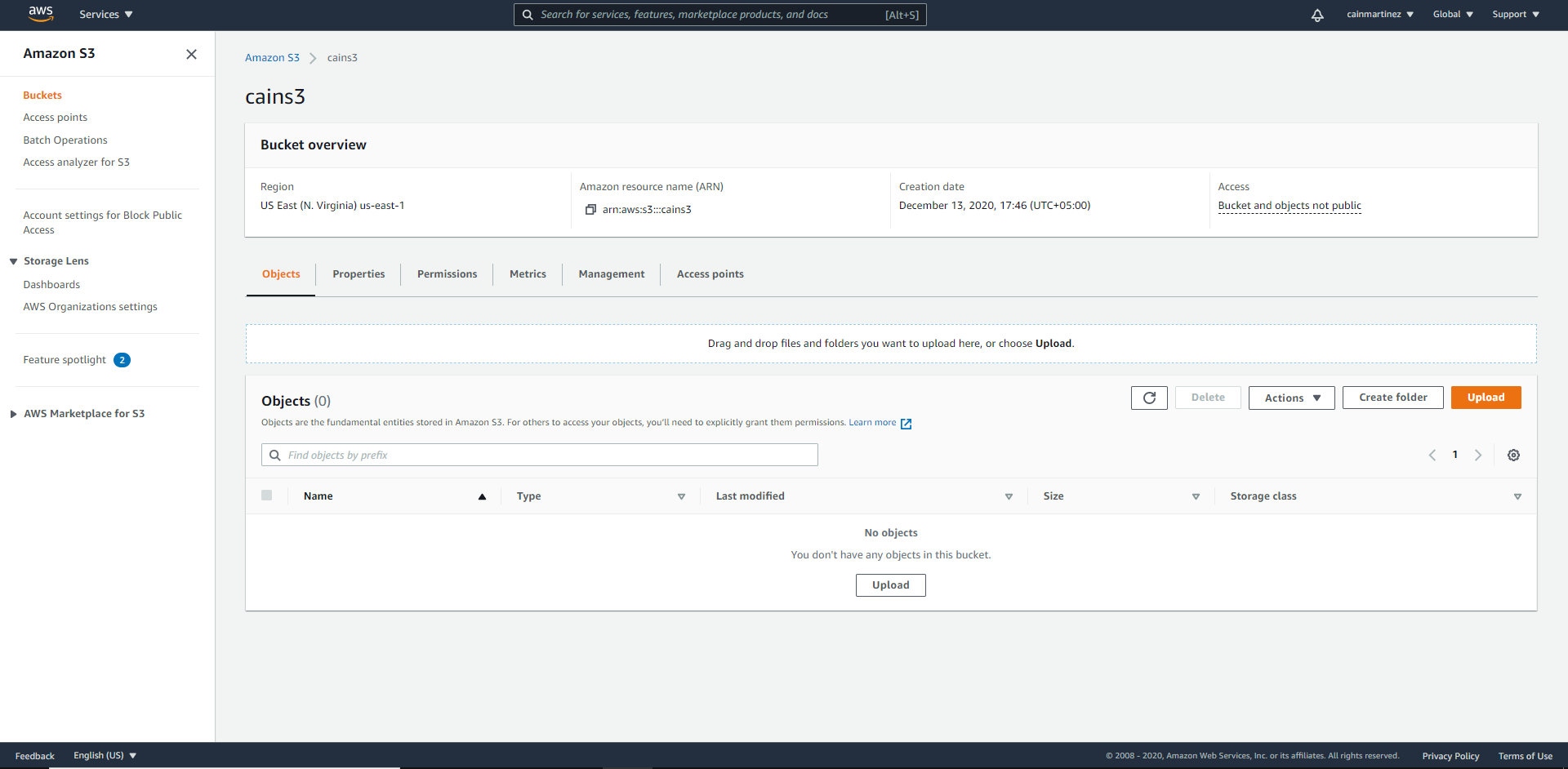
Compartiment AWS créé
Remarque : le compartiment créé et les objets qu’il contient ne sont pas publics.
Comment charger des fichiers dans le compartiment S3 créé ?
Pour charger des fichiers dans le compartiment S3, procédez comme suit :
1. Cliquez sur le nom du compartiment
2. Cliquez sur « Upload » (Charger)
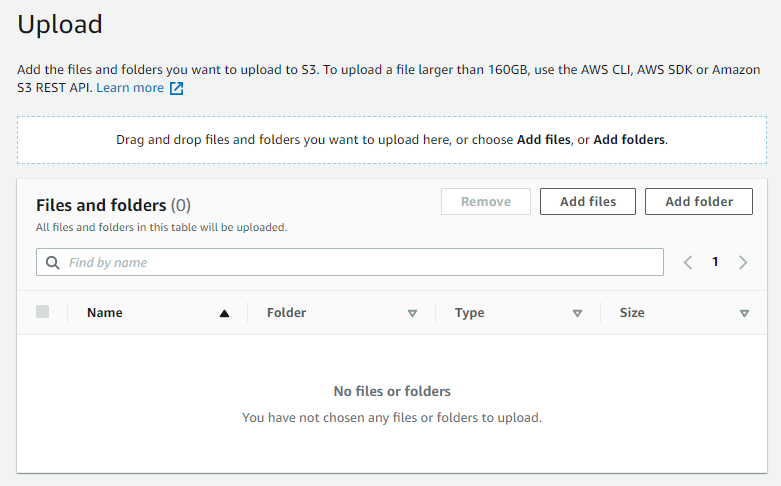
3. Cliquez sur « Add Files » (Ajouter des fichiers)
Ajoutez les fichiers voulus à partir du lecteur.
4. Cliquez sur le bouton « Upload » (Charger)
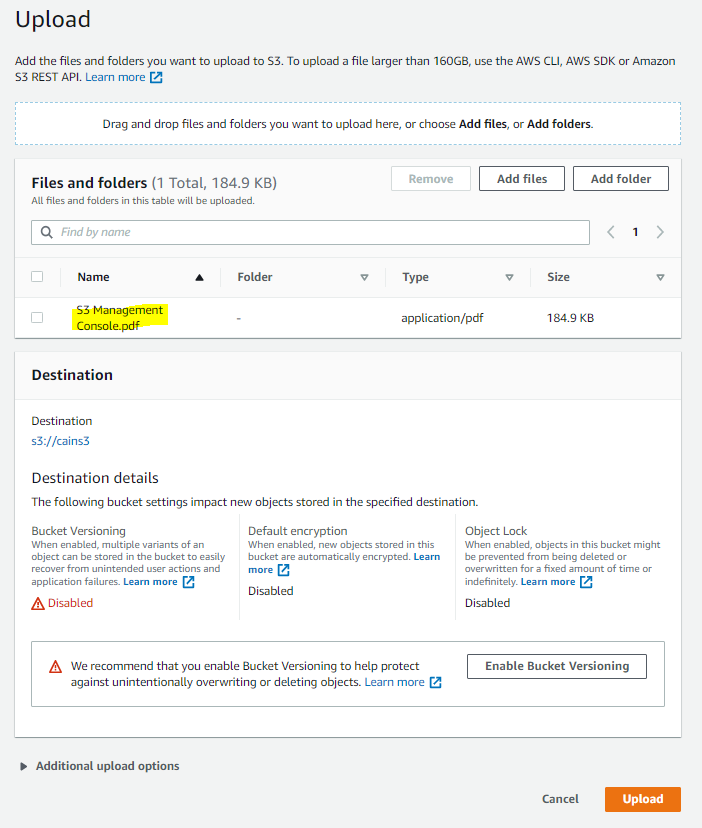
Écran indiquant l’état du chargement
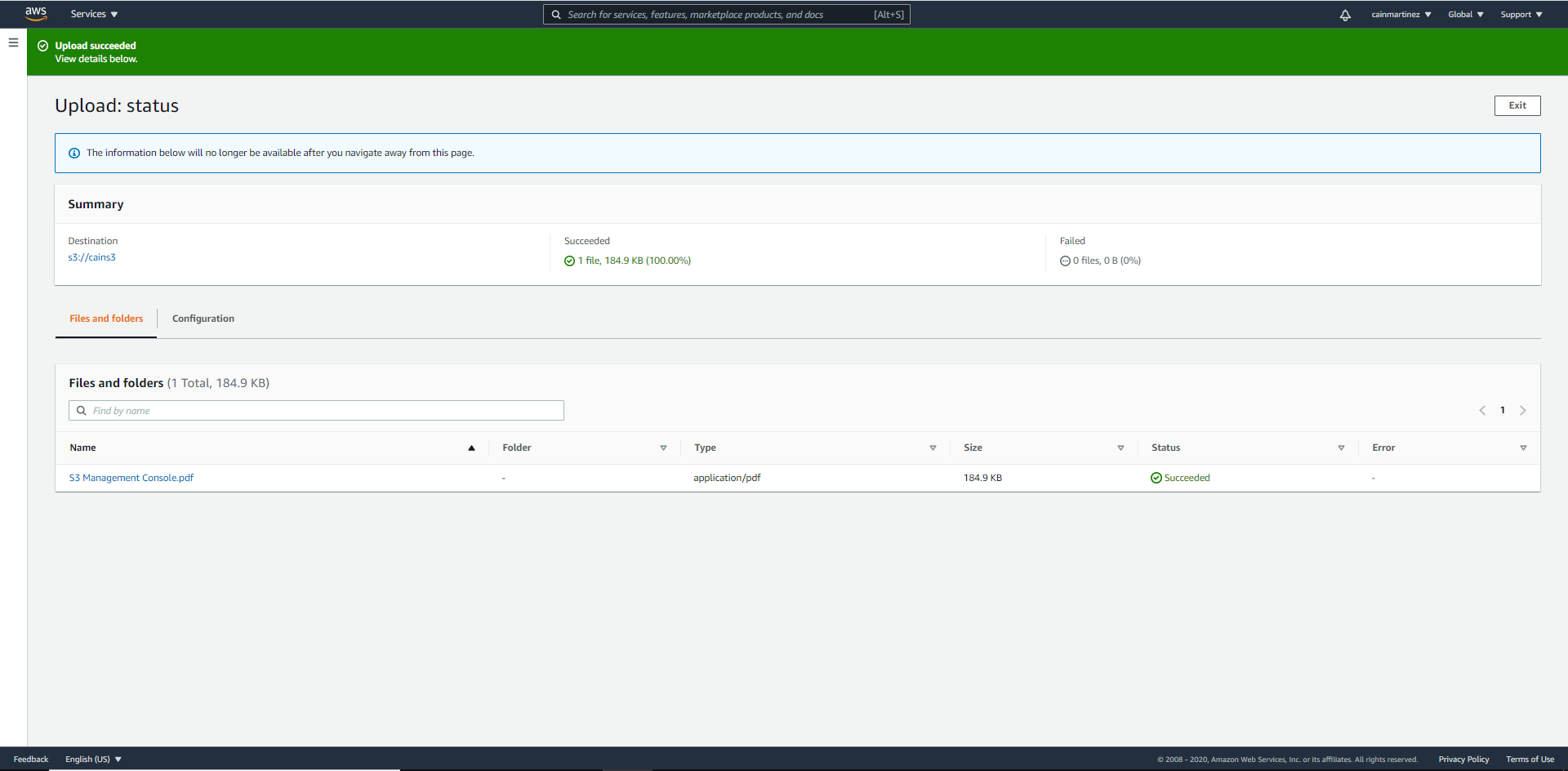
Nous constatons sur l’écran ci-dessus que le document se charge dans le compartiment que nous venons de créer.
Comment accéder aux données d’un compartiment AWS S3 ?
Pour accéder aux données d’un compartiment AWS S3, vous devez suivre chacune de ces étapes.
1. Cliquez sur le fichier
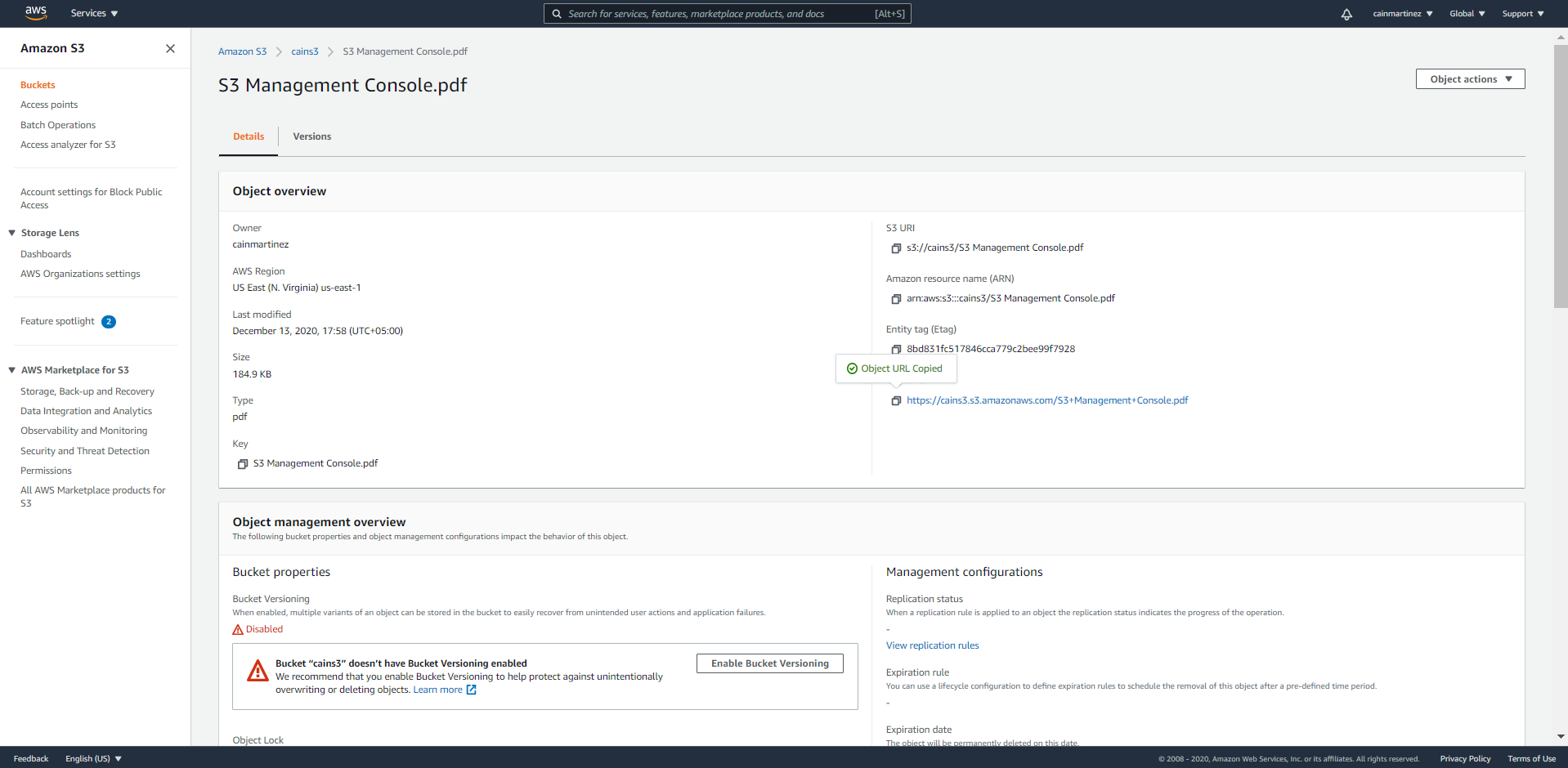
2. En accédant à l’URL, cet écran s’affiche :
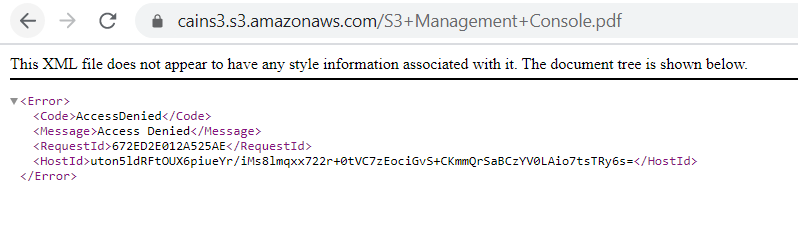
L’écran ci-dessus nous indique que nous n’avons pas accès aux objets du compartiment.
Pour résoudre ces problèmes, nous devons définir les autorisations du compartiment.
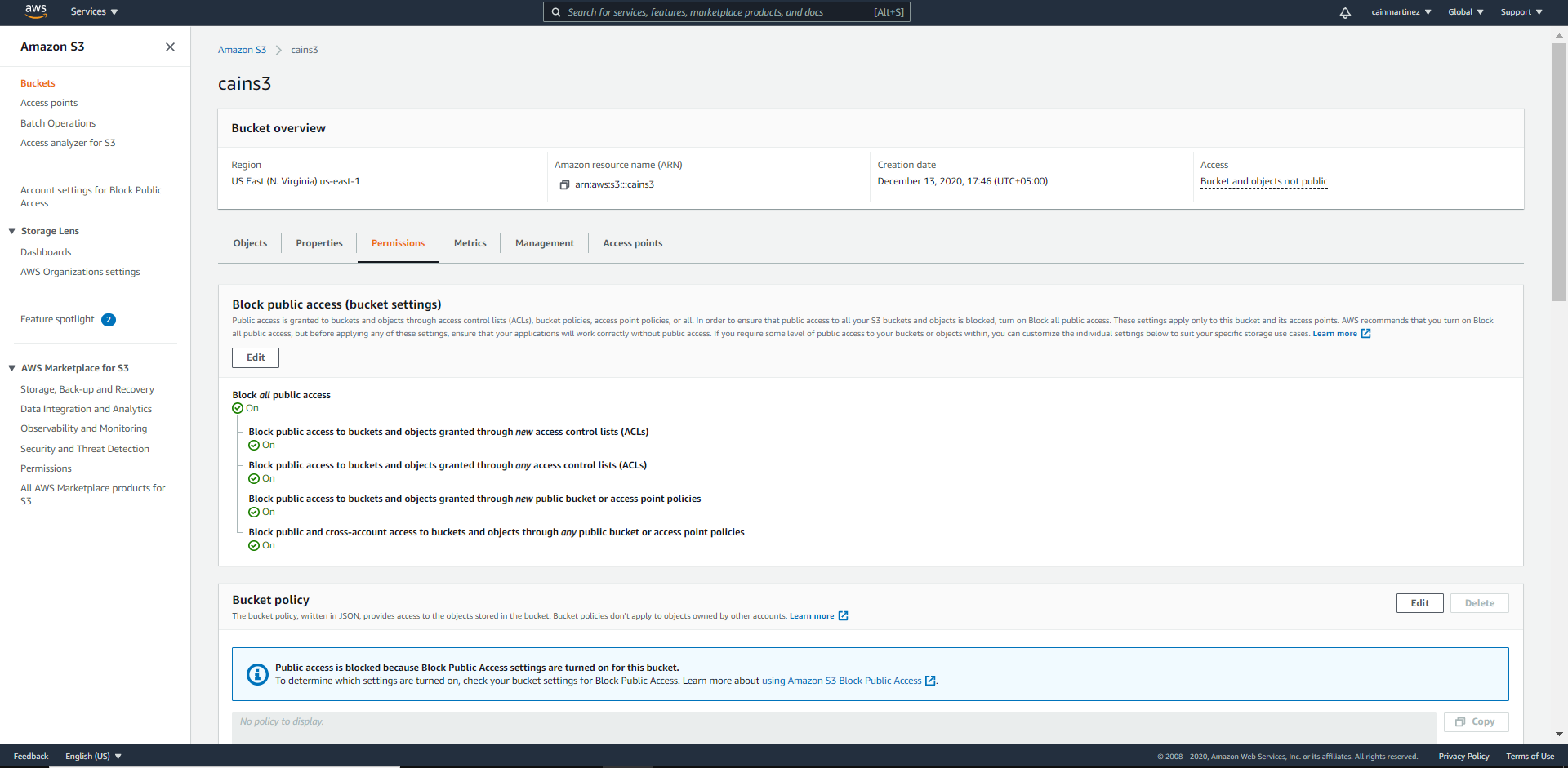
3. Accédez à « Bucket Permission » (Autorisations du compartiment)
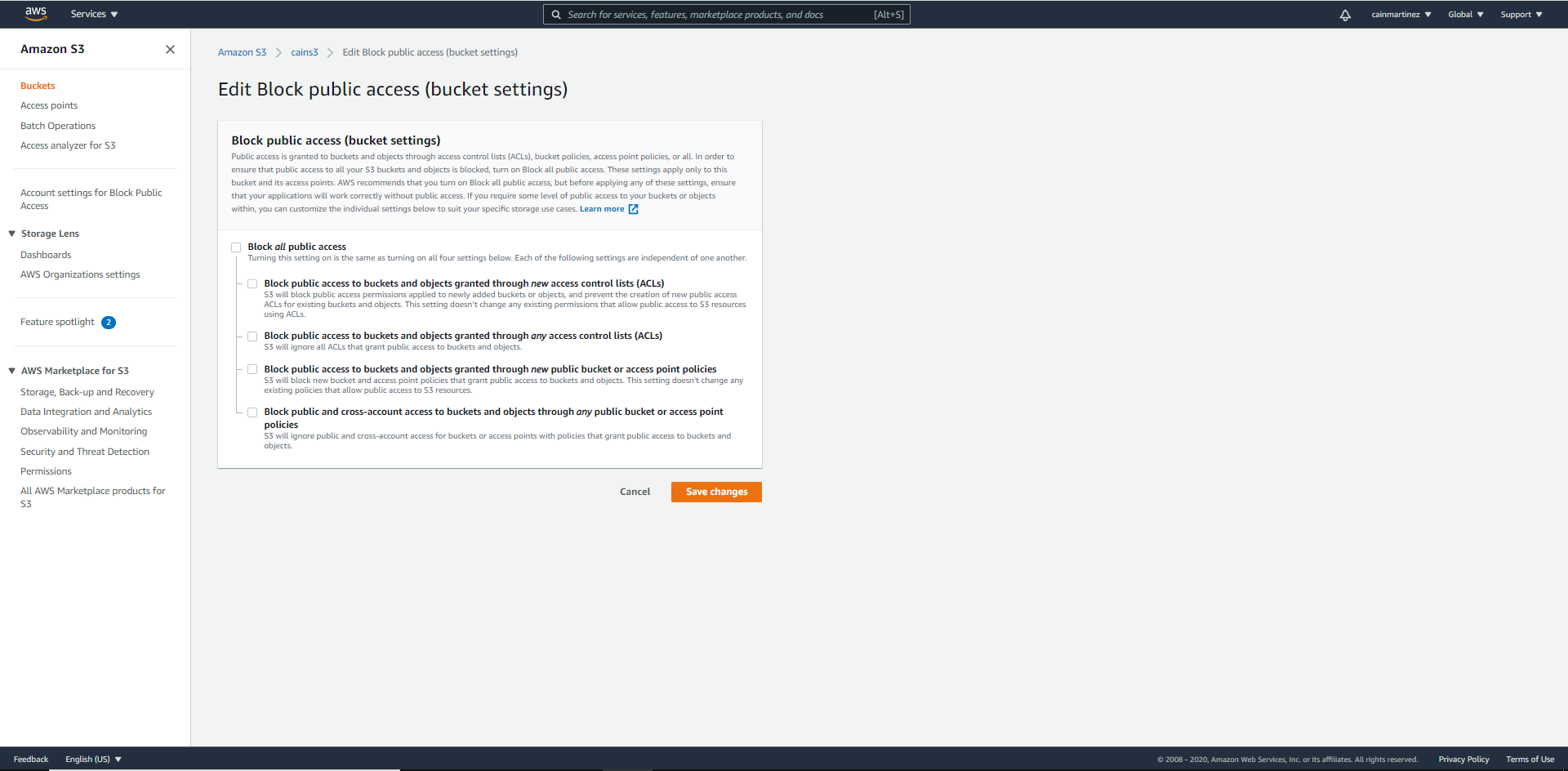
4. Cliquez sur « Edit » (Modifier) et désactivez l’option « Block All Public Access » (Bloquer tous les accès publics)
5. Cliquez sur « Save » (Enregistrer)
6. Rendez le fichier chargé public
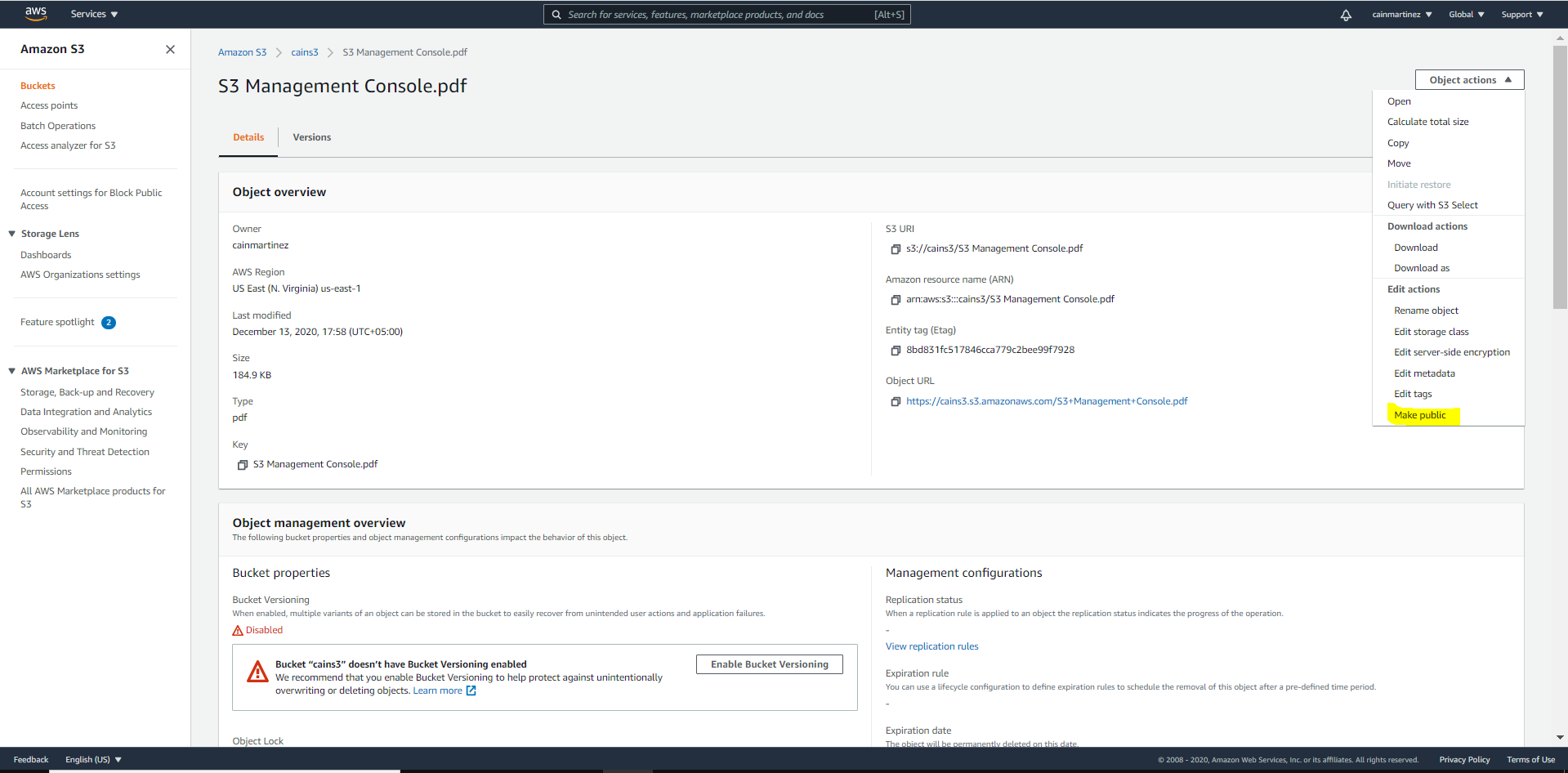
7. Maintenant, l’URL de l’objet est accessible
Concepts importants :
- Les compartiments constituent un espace de nom universel, c’est-à-dire que le nom du compartiment doit être unique.
- Si un objet se charge correctement dans le compartiment S3 créé, le code HTTP 200 est indiqué à l’écran.
- Stockage S3 à redondance réduite, S3 et S3 – Accès peu fréquent, correspondent aux classes de stockage.
- Il existe deux types de chiffrement : le chiffrement côté serveur et le chiffrement côté client.
- La gestion des accès au compartiment s’effectue par ACL (liste de contrôle d’accès) ou stratégies de compartiment.
- Par défaut, les compartiments et tous les objets qui s’y trouvent sont privés.
En termes de sécurité, le service AWS le plus vulnérable est indéniablement S3. Des compartiments S3 mal configurés sont à l’origine de fuites de données colossales au sein d’institutions de premier plan, telles que FedEx, Verizon, Dow Jones ou encore WEE. De telles fuites auraient pu être évitées, car AWS offre une sécurité de haut niveau lorsque la configuration est adéquate.
Examinons certaines bonnes pratiques de sécurité qui permettront d’améliorer la sécurité du compartiment AWS S3 :
Conseil 1 : Sécuriser les données avec le chiffrement de sécurité S3
Le chiffrement est une étape cruciale dans la sécurisation de vos données. S3 fournit deux modes de chiffrement pour protéger vos données inactives :
- Chiffrement côté serveur (SSE, Server-Side Encryption) : avec ce type de chiffrement, AWS chiffre et stocke les données brutes sur ses disques (dans des centres de données). Lorsque vous essayez de récupérer les données, AWS les lit sur ses disques et les déchiffre avant de vous les envoyer.
- Chiffrement côté client (CSE, Client-Side Encryption) : avec ce type de chiffrement, vous vous chargez de chiffrer les données avant de les envoyer à AWS. Lorsque AWS renvoie les données, les algorithmes de déchiffrement déchiffrent les données.
Votre choix dépendra de vos besoins et des impératifs de sécurité et de conformité auxquels vous êtes tenu. Vous pouvez choisir le chiffrement côté serveur si vous acceptez qu’AWS se charge du processus de chiffrement. Si les données sont sensibles et que vous préférez les chiffrer vous-même, choisissez le chiffrement côté client.
L’exemple ci-dessous illustre la protection SSE dans un compartiment S3 :
- Créez un compartiment S3 à partir du tableau de bord AWS S3.
- Ensuite, chargez les données dans le compartiment.
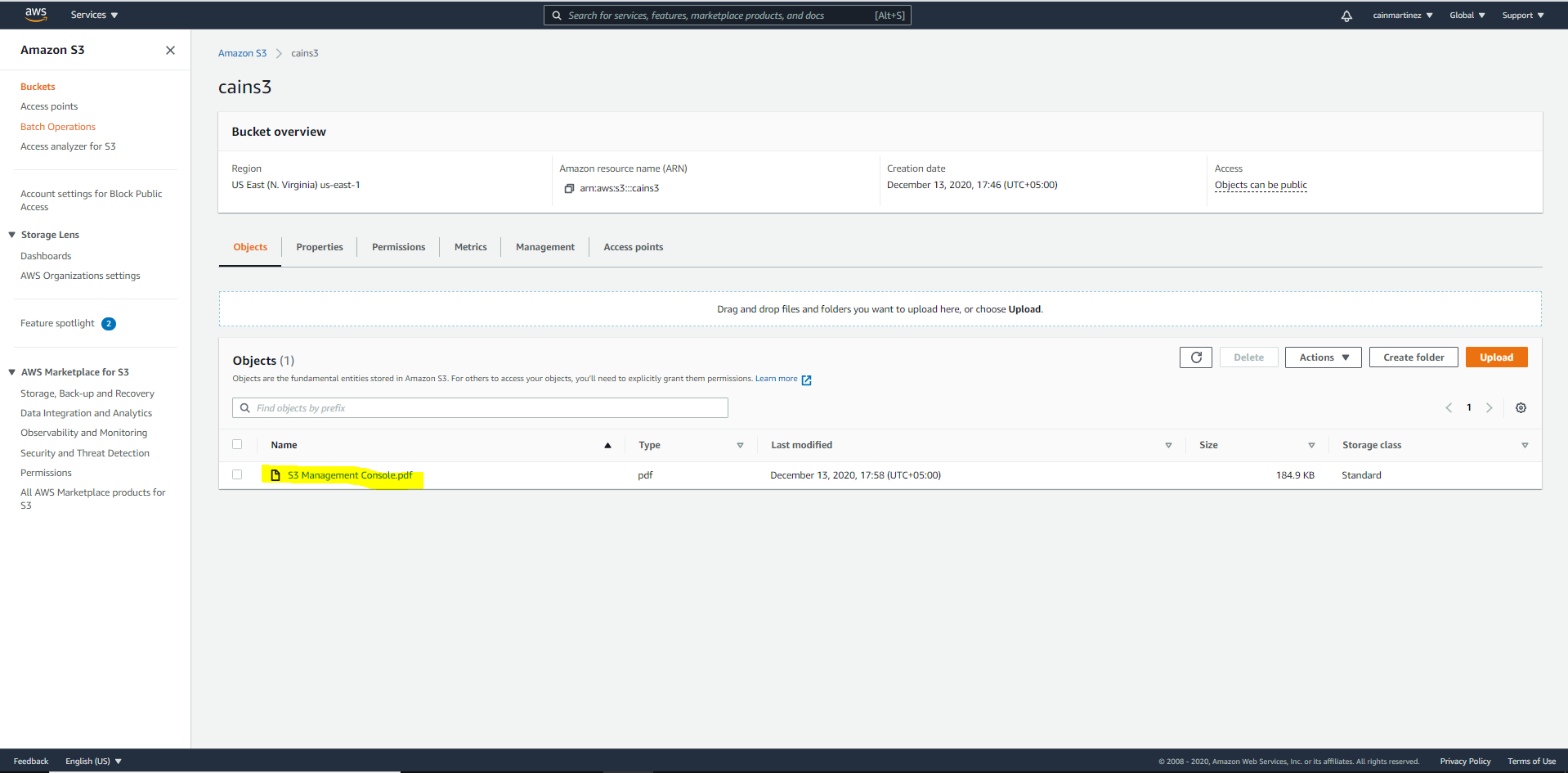
- Maintenant, cliquez sur l’objet chargé afin d’afficher les propriétés de chiffrement.
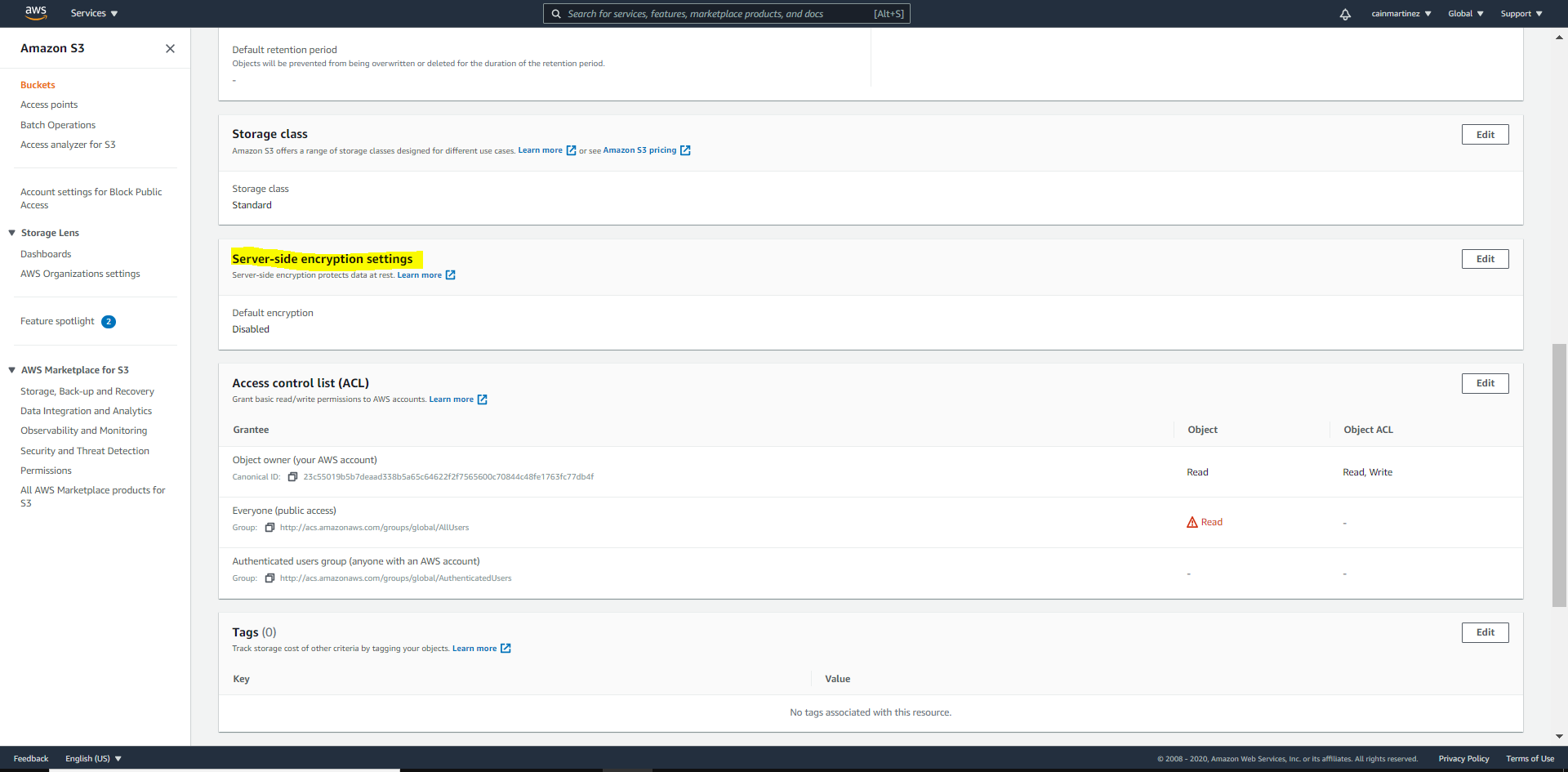
Par défaut, le chiffrement est désactivé.
- Cliquez sur le bouton « Edit » (Modifier) en regard de l’option de chiffrement.
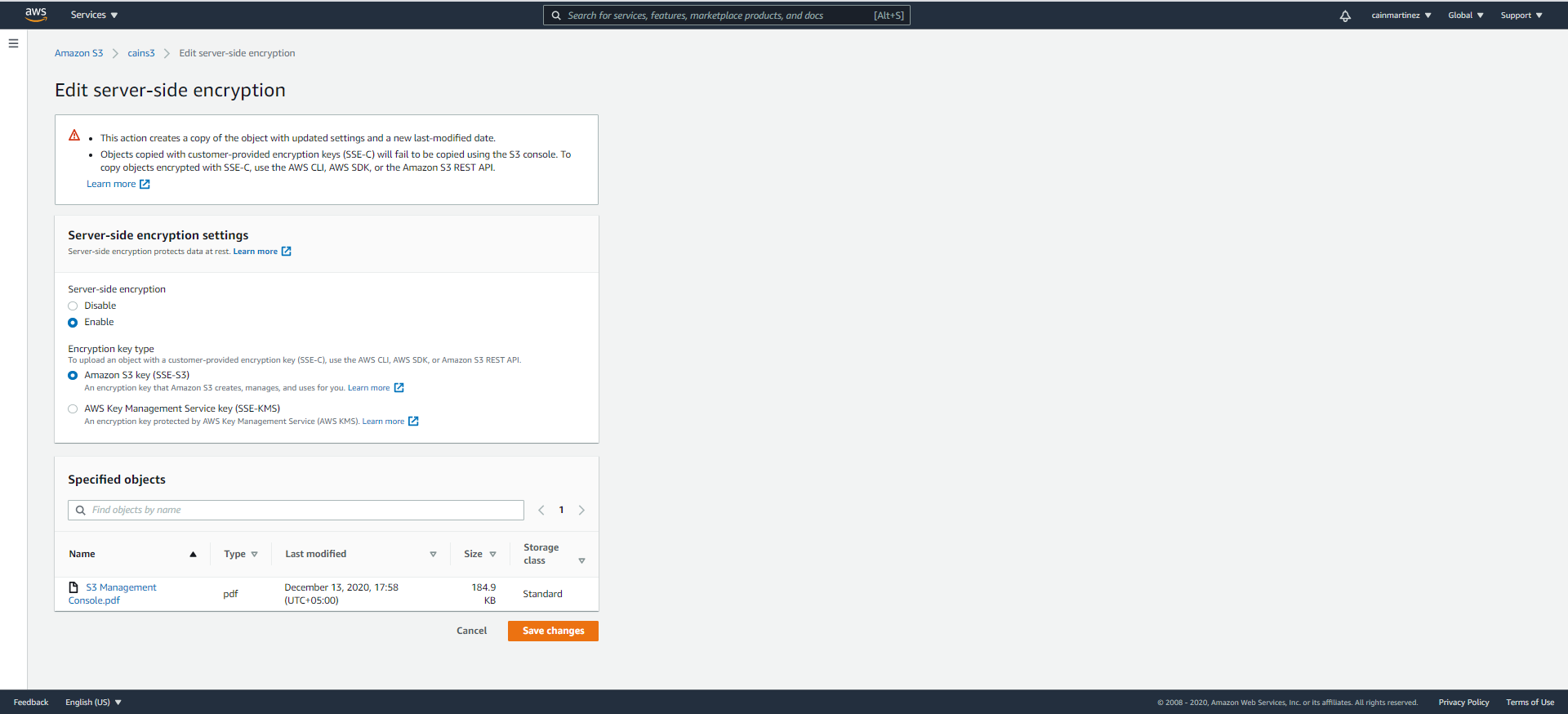
- Sélectionnez « Enable » (Activer) et cliquez sur « Amazon S3 key (SSE-S3) ». Cette option définit le chiffrement AES-256 côté serveur des données. Cliquez sur « Save changes » (Enregistrer les modifications).
Après quelques secondes, le nouveau type de chiffrement s’affiche à l’écran.

Fichiers chiffrés de manière sécurisée dans le compartiment S3.
Conseil 2 : Gérer le contrôle d’accès
Le contrôle d’accès est la composante essentielle d’une protection des données optimale. Nous avons répertorié cinq options pour gérer l’accès aux compartiments et ressources S3. Analysons chacune de ces méthodes pour vous aider à créer un mécanisme de sécurité éprouvé et efficace sur AWS S3 :
1. Restriction des autorisations utilisateur par IAM
Identity and Access Management (IAM) permet de contrôler les accès avec précision. En instaurant le principe du moindre privilège, l’administrateur peut accorder aux utilisateurs des autorisations d’accès et des ressources minimales pour gérer les compartiments et accéder aux données en lecture/écriture. Cette approche permet de minimiser le risque d’erreurs humaines, souvent à l’origine de la mauvaise configuration des compartiments S3 aboutissant à des fuites de données.
D’une manière générale, commencez par accorder un minimum d’autorisations et complétez-les progressivement en fonction des besoins.
2. Limitation des accès de sécurité S3 avec les stratégies de compartiment
Les stratégies de compartiment sont semblables aux stratégies d’utilisateurs IAM, à la différence qu’elles sont directement associées aux services de sécurité S3. Les stratégies de compartiment vous apportent de la polyvalence et vous permettent de gérer les accès au compartiment avec une granularité fine.
Dans certains cas, il est préférable d’utiliser des stratégies de compartiment. Nous examinerons ici quelques cas de figure types.
3. Utilisation des points d’accès S3 pour attribuer les stratégies d’accès
Amazon a lancé les points d’accès S3 lors de la conférence « Re-Invent 2019 » à Las Vegas. Cette fonctionnalité améliore le contrôle d’accès en utilisant des compartiments S3 d’usage mixte afin de faciliter la gestion des stratégies de compartiment.
Avant le lancement des points d’accès S3, les stratégies de compartiment servaient de support pour gérer toutes les données au sein d’un compartiment avec des autorisations variables. Les points d’accès S3 modernisent la gestion des données à grande échelle.
Comment fonctionnent les points d’accès S3 ?
Les points d’accès S3 sont dotés de noms d’hôtes uniques et de stratégies d’accès propres, qui expliquent comment traiter les données avec ce terminal. Les stratégies de point d’accès sont semblables aux stratégies de compartiment, si ce n’est qu’elles sont associées à un point d’accès particulier. Les points d’accès S3 peuvent aussi se limiter à un cloud privé virtuel (VPC) pour protéger les données S3 sur ce réseau privé. Ainsi, chaque point d’accès possède un nom DNS spécifique, ce qui facilite l’adressage des compartiments.
4. Utilisation des ACL pour superviser les accès
Avant qu’AWS IAM se généralise, l’accès à S3 était encadré par des listes de contrôle ou ACL (Access Control List). La mauvaise configuration des ACL explique en grande partie pourquoi les fuites de données sont si répandues sur S3.
Les ACL s’appliquent soit au niveau du compartiment, soit au niveau du composant. Pour faire simple, les ACL de compartiment permettent de contrôler l’accès au compartiment, tandis que les ACL d’objet permettent de contrôler l’accès au niveau des objets. Par défaut, les ACL de compartiment autorisent uniquement l’accès du titulaire du compte. Malgré tout, il est très simple de rendre les compartiments publics, c’est pourquoi AWS déconseille d’utiliser ces ACL.
5. Utilisation du blocage d’accès public d’Amazon S3
Enfin, Amazon propose un mécanisme centralisé pour limiter l’accès public aux services S3. Avec le blocage de l’accès public d’Amazon S3, vous pouvez contourner les stratégies de compartiment et les autorisations d’objet déjà établies. Notez que les paramètres de blocage fonctionnent pour les compartiments, les comptes AWS et les points d’accès.
Conseil 3 : Maximiser la fiabilité et la sécurité de S3 par la réplication
Les entreprises peuvent améliorer la sécurité et la fiabilité de S3 en adoptant une stratégie de protection des données axée sur une résilience maximale. Analysons cinq de ces bonnes pratiques de sécurité pour AWS S3 :
1. Constituer des copies des données
Cette approche, qui renforce la sécurité des données, est la plus courante. Le service AWS Backup, qui prend en charge la plupart des services AWS comme Amazon EFS, DynamoDB, RDS, EBS et Storage Gateway, vous permet de centraliser et d’automatiser les processus de sauvegarde.
2. Choisir les niveaux de disponibilité
Comme les ressources S3 sont proposées avec différents niveaux de disponibilité, utilisez le stockage avec accès peu fréquent pour les charges de travail de faible priorité, puis adoptez une classe de service supérieure pour les charges IT nécessitant une disponibilité plus élevée. Vous avez la garantie d’optimiser votre stockage en fonction des exigences de charges de travail, sachant qu’un surinvestissement en la matière devient vite coûteux.
3. Utiliser le contrôle de version S3
Les risques d’incidents et de défaillances des infrastructures font aussi peser des menaces importantes sur les données. En envisageant de recourir au contrôle de version S3 pour récupérer des fichiers perdus, vous pouvez vous éviter des processus de sauvegarde et récupération complexes et laborieux. Le processus de contrôle de version S3 prévoit l’enregistrement d’une version des objets du compartiment S3 à chaque action PUT, COPY, POST ou Remove.
4. Utiliser la réplication CRR
La fonctionnalité Cross-Region Replication (CRR) permet de résoudre la question des points uniques de défaillance tout en accroissant la disponibilité des données. Outre la disponibilité, CRR aide également à respecter les obligations réglementaires si vous devez stocker des données dans différentes zones géographiques.
5. Utiliser la réplication SRR
La fonctionnalité Same-Region Replication (SRR) est un excellent choix si la réglementation impose de stocker les données localement ou dans la même région. AWS s’appuie sur une fonction intégrée de réplication des données qui duplique le compartiment S3 sur des dispositifs de stockage répartis dans trois zones de disponibilité à l’échelle de la région. Cela garantit la protection et la durabilité des données en cas de défaillance des infrastructures ou d’incident.
Conseil 4 : Appliquer le protocole SSL pour sécuriser S3
SSL est le protocole le plus adapté pour sécuriser les liaisons de communication avec compartiments S3. Par défaut, les données de compartiments S3 sont accessibles via HTTP ou HTTPS ; un attaquant est donc susceptible d’accéder à vos requêtes S3 avec la technique de l’homme du milieu (man-in-the-middle).
Conseil 5 : Utiliser la journalisation
La journalisation des accès au compartiment S3 est une fonction qui réunit des informations sur toutes les requêtes envoyées au compartiment, comme les comportements PUT, GET ou DELETE. Avec elle, l’équipe de sécurité a les moyens de détecter les tentatives d’activités malveillantes à l’intérieur de vos compartiments.
La journalisation est une pratique de sécurité recommandée, car elle aide les équipes à se conformer aux obligations réglementaires, à détecter les accès non autorisés aux données ou à enquêter sur une fuite de données.
Conseil 6 : Utilisez le verrouillage des objets S3
Avec le verrouillage des objets S3, il est très difficile de supprimer des données de S3. Pour porter atteinte aux données des organisations, les acteurs malveillants procèdent essentiellement de deux manières :
En supprimant les données
En dérobant les données
Le verrouillage des objets S3 permet d’empêcher ou d’ignorer la suppression d’un objet. Pour rendre l’objet S3 immuable, il existe deux possibilités : soit on définit une période de rétention, soit on maintient une mise en suspens juridique sur l’objet jusqu’à sa suppression.
Le verrouillage des objets S3 permet aussi de respecter les obligations réglementaires WORM ou de créer des couches de protection supplémentaires à des fins de conformité exclusivement.
Suivez les étapes ci-après pour activer le verrouillage des objets lors de la création d’un compartiment S3 :
- Dans la console de gestion AWS, accédez à S3 sous « Storage » (Stockage) , puis cliquez sur « Create bucket » (Créer un compartiment).
- Après avoir saisi le nom du compartiment, vous trouverez une case d’option sous « Objet Lock » (Verrouillage d’objet) à la section « Advanced Settings » (Paramètres avancés), comme illustré ci-dessous :
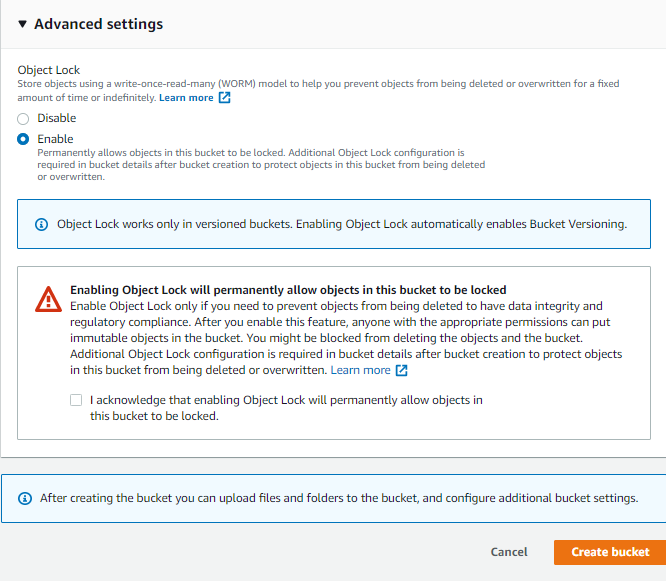
- Cliquez sur l’option « enable » (activer) ; un message confirmant le verrouillage de l’objet s’affiche. Vous pouvez cliquer sur « Next » (Suivant) et poursuivre la création du compartiment.
Remarque : le verrouillage des objets fonctionne uniquement lorsque la gestion des versions est active.
Il est essentiel de bien gérer et configurer vos compartiments AWS S3 pour disposer d’une infrastructure sécurisée, quel que soit le lieu d’hébergement des serveurs. Les étapes présentées dans ce guide ne sont qu’un début. Pour mettre en place une stratégie de cybersécurité complète, il est également nécessaire de prévoir une supervision constante des accès aux données afin de détecter des anomalies et d’éventuels incidents. Varonis a acquis Polyrize afin de mieux relever le défi de la sécurité sur la nouvelle frontière du cloud.
Cliquez ici pour organiser un appel avec nos experts en cybersécurité, qui vous présenteront comment Varonis peut vous aider à gérer votre infrastructure cloud.
Utilisez AWS S3 en toute sécurité : Guide de configuration
Contenu
Amazon a ouvert la voie de l’Infrastructure-as-a-service (IaaS) avec son offre Amazon Web Services. Que ce soit Netflix, la NASA ou la marine américaine, tous ont choisi Amazon en tant que back-end. AWS S3 est le service de stockage d’AWS, et la cause de plusieurs fuites de données majeures.
Cet article de blog présente les fondamentaux d’AWS S3 et explique comment sécuriser le système afin de prévenir les incidents de cybersécurité.
Qu’est-ce qu’AWS S3 (Simple Storage Service) ?
AWS S3 est l’un des services fondamentaux de l’infrastructure AWS. D’un point de vue conceptuel, c’est l’équivalent d’un serveur de fichiers d’une capacité infinie, situé sur un site distant ou un serveur FTP.
Amazon S3 stocke les données chargées sous forme d’objets dans des « compartiments ». Plutôt que d’utiliser des serveurs de fichiers, la structure de S3 s’organise en compartiments et en objets.
Un objet peut être un fichier DOC ou vidéo, accompagné de métadonnées qui le décrivent. Les compartiments sont les conteneurs qui accueillent un objet. Les administrateurs peuvent configurer et gérer l’accès à chaque compartiment (c’est-à-dire déterminer et contrôler qui peut créer, supprimer et lister les éléments du compartiment), consulter les journaux d’accès au compartiment et aux objets qu’il contient et choisir la zone géographique dans laquelle Amazon S3 conserve le compartiment et son contenu.
Types de stockage d’une configuration Amazon S3
Amazon a mis au point Amazon S3 comme une solution durable et flexible qui offre de nombreuses possibilités de stockage pour répondre aux besoins spécifiques de ses clients, à savoir :
Dans quel cas utiliser AWS S3 ?
Il existe une diversité de cas d’usage pour AWS S3 ; en voici quelques-uns.
Stockage Internet
Amazon S3 convient parfaitement au stockage d’images applicatives et de vidéos nécessitant des performances de rendu élevées. Tous les services AWS (y compris Amazon Prime et Amazon.com), mais aussi Netflix et Airbnb, utilisent Amazon S3 à cette fin.
Reprise après incident et sauvegarde
Le service Amazon S3 est parfait pour stocker et archiver des données très sensibles ou des sauvegardes. Le stockage, qui est automatiquement distribué entre plusieurs régions, offre les niveaux les plus élevés de disponibilité et de durabilité. Vous pouvez faciliter la restauration des fichiers ou des versions antérieures grâce au contrôle de version Amazon S3. La perte d’informations est très peu probable avec Amazon S3 si vous privilégiez des objectifs de point de récupération (RPO) et de délai de récupération (RTO) peu élevés.
Analytique
Amazon S3 offre des fonctionnalités avancées d’interrogation sur site pour effectuer des analyses très efficaces des données S3. Il est ainsi inutile de déplacer les données et de prévoir un stockage spécifique, puisque S3 facilite la plupart des services faisant intervenir des tiers.
Archivage des données
Les utilisateurs peuvent stocker leurs données et les transférer d’Amazon S3 vers Amazon Glacier, une solution d’archivage conforme, durable et peu coûteuse. Il est également possible d’automatiser les données archivées avec une stratégie de cycle de vie qui favorise la gestion des données avec un minimum d’effort.
Hébergement de site Web statique
Amazon S3 stocke différents types d’objets statiques. L’hébergement de sites Web statiques est donc un cas d’usage important. De plus en plus d’applications Web étant des pages uniques ou des sites statiques (Angular, ReactJS, etc.), le recours à un serveur Web est coûteux. S3 fournit une fonctionnalité d’hébergement de sites Web statiques qui permet d’utiliser votre nom de domaine sans engager de frais d’hébergement importants.
Sécurité et conformité
Amazon S3 offre plusieurs fonctions de chiffrement et de conformité pour les normes PCI-DSS, HIPAA/HITECH, FedRAMP, FISMA, etc. Grâce à elles, les clients peuvent remplir les critères de conformité imposés partout dans le monde par les organismes de réglementation… Et il est plus facile de restreindre l’accès aux données sensibles avec des stratégies de compartiments.
Comment utiliser AWS S3 ?
Toutes les données S3 résident dans des compartiments mondiaux spéciaux, avec plusieurs répertoires et sous-dossiers. Choisissez une région lors de la création du compartiment pour optimiser la latence et réduire les coûts d’accès aux données. Pour configurer Amazon S3, procédez comme suit :
Créez un compartiment S3
Vous trouverez ci-dessous des instructions et des captures d’écran pour créer un compartiment S3.
1. Connectez-vous
Ouvrez un compte pour la console de gestion AWS. Une fois connecté, vous arrivez sur l’écran ci-dessous.
2. Recherchez « S3 »
Saisissez « S3 » dans la barre de recherche et validez.
Le tableau de bord AWS S3 doit se présenter comme suit.
3. Cliquez sur « Create bucket » (Créer un compartiment)
Cliquez sur le bouton « Create bucket » pour créer un compartiment S3. Une fois que vous avez cliqué, vous accédez à cet écran :
4. Nommez le compartiment
Saisissez le nom de votre compartiment.
Il existe plusieurs manières de configurer les autorisations de votre compartiment S3. L’autorisation par défaut est « Private » (Privé), mais il est possible de la modifier via la console de gestion AWS ou une stratégie de compartiment. En termes de sécurité, il est recommandé d’être sélectif lorsque vous accordez l’accès aux compartiments S3 que vous créez. Ajoutez uniquement les autorisations nécessaires et évitez d’ouvrir le compartiment au public.
5. Configurez les options (facultatif)
Vous pouvez choisir les fonctions à activer pour un compartiment donné, par exemple :
6. Créez le compartiment
Pour finir, cliquez sur « Create bucket » (Créer un compartiment).
Compartiment AWS créé
Remarque : le compartiment créé et les objets qu’il contient ne sont pas publics.
Comment charger des fichiers dans le compartiment S3 créé ?
Pour charger des fichiers dans le compartiment S3, procédez comme suit :
1. Cliquez sur le nom du compartiment
2. Cliquez sur « Upload » (Charger)
3. Cliquez sur « Add Files » (Ajouter des fichiers)
Ajoutez les fichiers voulus à partir du lecteur.
4. Cliquez sur le bouton « Upload » (Charger)
Écran indiquant l’état du chargement
Nous constatons sur l’écran ci-dessus que le document se charge dans le compartiment que nous venons de créer.
Comment accéder aux données d’un compartiment AWS S3 ?
Pour accéder aux données d’un compartiment AWS S3, vous devez suivre chacune de ces étapes.
1. Cliquez sur le fichier
2. En accédant à l’URL, cet écran s’affiche :
L’écran ci-dessus nous indique que nous n’avons pas accès aux objets du compartiment.
Pour résoudre ces problèmes, nous devons définir les autorisations du compartiment.
3. Accédez à « Bucket Permission » (Autorisations du compartiment)
4. Cliquez sur « Edit » (Modifier) et désactivez l’option « Block All Public Access » (Bloquer tous les accès publics)
5. Cliquez sur « Save » (Enregistrer)
6. Rendez le fichier chargé public
7. Maintenant, l’URL de l’objet est accessible
Concepts importants :
Comment configurer AWS S3 ?
En termes de sécurité, le service AWS le plus vulnérable est indéniablement S3. Des compartiments S3 mal configurés sont à l’origine de fuites de données colossales au sein d’institutions de premier plan, telles que FedEx, Verizon, Dow Jones ou encore WEE. De telles fuites auraient pu être évitées, car AWS offre une sécurité de haut niveau lorsque la configuration est adéquate.
Examinons certaines bonnes pratiques de sécurité qui permettront d’améliorer la sécurité du compartiment AWS S3 :
Conseil 1 : Sécuriser les données avec le chiffrement de sécurité S3
Le chiffrement est une étape cruciale dans la sécurisation de vos données. S3 fournit deux modes de chiffrement pour protéger vos données inactives :
Votre choix dépendra de vos besoins et des impératifs de sécurité et de conformité auxquels vous êtes tenu. Vous pouvez choisir le chiffrement côté serveur si vous acceptez qu’AWS se charge du processus de chiffrement. Si les données sont sensibles et que vous préférez les chiffrer vous-même, choisissez le chiffrement côté client.
L’exemple ci-dessous illustre la protection SSE dans un compartiment S3 :
Par défaut, le chiffrement est désactivé.
Après quelques secondes, le nouveau type de chiffrement s’affiche à l’écran.
Fichiers chiffrés de manière sécurisée dans le compartiment S3.
Conseil 2 : Gérer le contrôle d’accès
Le contrôle d’accès est la composante essentielle d’une protection des données optimale. Nous avons répertorié cinq options pour gérer l’accès aux compartiments et ressources S3. Analysons chacune de ces méthodes pour vous aider à créer un mécanisme de sécurité éprouvé et efficace sur AWS S3 :
1. Restriction des autorisations utilisateur par IAM
Identity and Access Management (IAM) permet de contrôler les accès avec précision. En instaurant le principe du moindre privilège, l’administrateur peut accorder aux utilisateurs des autorisations d’accès et des ressources minimales pour gérer les compartiments et accéder aux données en lecture/écriture. Cette approche permet de minimiser le risque d’erreurs humaines, souvent à l’origine de la mauvaise configuration des compartiments S3 aboutissant à des fuites de données.
D’une manière générale, commencez par accorder un minimum d’autorisations et complétez-les progressivement en fonction des besoins.
2. Limitation des accès de sécurité S3 avec les stratégies de compartiment
Les stratégies de compartiment sont semblables aux stratégies d’utilisateurs IAM, à la différence qu’elles sont directement associées aux services de sécurité S3. Les stratégies de compartiment vous apportent de la polyvalence et vous permettent de gérer les accès au compartiment avec une granularité fine.
Dans certains cas, il est préférable d’utiliser des stratégies de compartiment. Nous examinerons ici quelques cas de figure types.
3. Utilisation des points d’accès S3 pour attribuer les stratégies d’accès
Amazon a lancé les points d’accès S3 lors de la conférence « Re-Invent 2019 » à Las Vegas. Cette fonctionnalité améliore le contrôle d’accès en utilisant des compartiments S3 d’usage mixte afin de faciliter la gestion des stratégies de compartiment.
Avant le lancement des points d’accès S3, les stratégies de compartiment servaient de support pour gérer toutes les données au sein d’un compartiment avec des autorisations variables. Les points d’accès S3 modernisent la gestion des données à grande échelle.
Comment fonctionnent les points d’accès S3 ?
Les points d’accès S3 sont dotés de noms d’hôtes uniques et de stratégies d’accès propres, qui expliquent comment traiter les données avec ce terminal. Les stratégies de point d’accès sont semblables aux stratégies de compartiment, si ce n’est qu’elles sont associées à un point d’accès particulier. Les points d’accès S3 peuvent aussi se limiter à un cloud privé virtuel (VPC) pour protéger les données S3 sur ce réseau privé. Ainsi, chaque point d’accès possède un nom DNS spécifique, ce qui facilite l’adressage des compartiments.
4. Utilisation des ACL pour superviser les accès
Avant qu’AWS IAM se généralise, l’accès à S3 était encadré par des listes de contrôle ou ACL (Access Control List). La mauvaise configuration des ACL explique en grande partie pourquoi les fuites de données sont si répandues sur S3.
Les ACL s’appliquent soit au niveau du compartiment, soit au niveau du composant. Pour faire simple, les ACL de compartiment permettent de contrôler l’accès au compartiment, tandis que les ACL d’objet permettent de contrôler l’accès au niveau des objets. Par défaut, les ACL de compartiment autorisent uniquement l’accès du titulaire du compte. Malgré tout, il est très simple de rendre les compartiments publics, c’est pourquoi AWS déconseille d’utiliser ces ACL.
5. Utilisation du blocage d’accès public d’Amazon S3
Enfin, Amazon propose un mécanisme centralisé pour limiter l’accès public aux services S3. Avec le blocage de l’accès public d’Amazon S3, vous pouvez contourner les stratégies de compartiment et les autorisations d’objet déjà établies. Notez que les paramètres de blocage fonctionnent pour les compartiments, les comptes AWS et les points d’accès.
Conseil 3 : Maximiser la fiabilité et la sécurité de S3 par la réplication
Les entreprises peuvent améliorer la sécurité et la fiabilité de S3 en adoptant une stratégie de protection des données axée sur une résilience maximale. Analysons cinq de ces bonnes pratiques de sécurité pour AWS S3 :
1. Constituer des copies des données
Cette approche, qui renforce la sécurité des données, est la plus courante. Le service AWS Backup, qui prend en charge la plupart des services AWS comme Amazon EFS, DynamoDB, RDS, EBS et Storage Gateway, vous permet de centraliser et d’automatiser les processus de sauvegarde.
2. Choisir les niveaux de disponibilité
Comme les ressources S3 sont proposées avec différents niveaux de disponibilité, utilisez le stockage avec accès peu fréquent pour les charges de travail de faible priorité, puis adoptez une classe de service supérieure pour les charges IT nécessitant une disponibilité plus élevée. Vous avez la garantie d’optimiser votre stockage en fonction des exigences de charges de travail, sachant qu’un surinvestissement en la matière devient vite coûteux.
3. Utiliser le contrôle de version S3
Les risques d’incidents et de défaillances des infrastructures font aussi peser des menaces importantes sur les données. En envisageant de recourir au contrôle de version S3 pour récupérer des fichiers perdus, vous pouvez vous éviter des processus de sauvegarde et récupération complexes et laborieux. Le processus de contrôle de version S3 prévoit l’enregistrement d’une version des objets du compartiment S3 à chaque action PUT, COPY, POST ou Remove.
4. Utiliser la réplication CRR
La fonctionnalité Cross-Region Replication (CRR) permet de résoudre la question des points uniques de défaillance tout en accroissant la disponibilité des données. Outre la disponibilité, CRR aide également à respecter les obligations réglementaires si vous devez stocker des données dans différentes zones géographiques.
5. Utiliser la réplication SRR
La fonctionnalité Same-Region Replication (SRR) est un excellent choix si la réglementation impose de stocker les données localement ou dans la même région. AWS s’appuie sur une fonction intégrée de réplication des données qui duplique le compartiment S3 sur des dispositifs de stockage répartis dans trois zones de disponibilité à l’échelle de la région. Cela garantit la protection et la durabilité des données en cas de défaillance des infrastructures ou d’incident.
Conseil 4 : Appliquer le protocole SSL pour sécuriser S3
SSL est le protocole le plus adapté pour sécuriser les liaisons de communication avec compartiments S3. Par défaut, les données de compartiments S3 sont accessibles via HTTP ou HTTPS ; un attaquant est donc susceptible d’accéder à vos requêtes S3 avec la technique de l’homme du milieu (man-in-the-middle).
Conseil 5 : Utiliser la journalisation
La journalisation des accès au compartiment S3 est une fonction qui réunit des informations sur toutes les requêtes envoyées au compartiment, comme les comportements PUT, GET ou DELETE. Avec elle, l’équipe de sécurité a les moyens de détecter les tentatives d’activités malveillantes à l’intérieur de vos compartiments.
La journalisation est une pratique de sécurité recommandée, car elle aide les équipes à se conformer aux obligations réglementaires, à détecter les accès non autorisés aux données ou à enquêter sur une fuite de données.
Conseil 6 : Utilisez le verrouillage des objets S3
Avec le verrouillage des objets S3, il est très difficile de supprimer des données de S3. Pour porter atteinte aux données des organisations, les acteurs malveillants procèdent essentiellement de deux manières :
En supprimant les données
En dérobant les données
Le verrouillage des objets S3 permet d’empêcher ou d’ignorer la suppression d’un objet. Pour rendre l’objet S3 immuable, il existe deux possibilités : soit on définit une période de rétention, soit on maintient une mise en suspens juridique sur l’objet jusqu’à sa suppression.
Le verrouillage des objets S3 permet aussi de respecter les obligations réglementaires WORM ou de créer des couches de protection supplémentaires à des fins de conformité exclusivement.
Suivez les étapes ci-après pour activer le verrouillage des objets lors de la création d’un compartiment S3 :
Remarque : le verrouillage des objets fonctionne uniquement lorsque la gestion des versions est active.
Il est essentiel de bien gérer et configurer vos compartiments AWS S3 pour disposer d’une infrastructure sécurisée, quel que soit le lieu d’hébergement des serveurs. Les étapes présentées dans ce guide ne sont qu’un début. Pour mettre en place une stratégie de cybersécurité complète, il est également nécessaire de prévoir une supervision constante des accès aux données afin de détecter des anomalies et d’éventuels incidents. Varonis a acquis Polyrize afin de mieux relever le défi de la sécurité sur la nouvelle frontière du cloud.
Cliquez ici pour organiser un appel avec nos experts en cybersécurité, qui vous présenteront comment Varonis peut vous aider à gérer votre infrastructure cloud.
What you should do now
Below are three ways we can help you begin your journey to reducing data risk at your company:
Michael Buckbee
Michael a travaillé en tant qu'administrateur système et développeur de logiciels pour des start-ups de la Silicon Valley, la marine américaine, et tout ce qui se trouve entre les deux.