
Définition de la classification des données
Pour protéger vos données sensibles, vous devez les identifier et savoir où elles se trouvent.
La classification des données est le processus consistant à analyser des données structurées ou non structurées et à les organiser en catégories, en fonction du type et du contenu des fichiers.
Apprennez à protéger du vol, les données sensibles surexposées sur votre réseau.
Le processus de classification des données implique la recherche de certaines chaînes de données dans les fichiers, un peu comme si vous vouliez trouver toutes les références à « sauce Sichuan » contenues dans votre réseau. Ou si vous deviez savoir où se trouvent toutes les données protégées par le HIPAA. Ou si vous désiriez vous préparer aux réglementations sur la confidentialité des données et trouver toutes les informations personnelles identifiables contenues dans vos dépôts de données.

La classification des données est en général basée sur la combinaison d’un analyseur de fichiers et d’un système d’analyse de chaîne. Un analyseur de fichiers permet au moteur de classification des données de lire le contenu de plusieurs types de fichier différents. Un système d’analyse de chaîne compare ensuite les données contenues dans ces fichiers à des paramètres de recherche prédéfinis.
Les RegEx –raccourci pour regular expression (expression régulière) – qui constituent l’un des systèmes d’analyse de chaîne les plus répandus, définissent les caractéristiques de modèles de recherche. Par exemple, si je veux trouver dans mes données tous les numéros de cartes de crédit VISA, je peux utiliser une RegEx ressemblant à :
\b(?<![:$._’-])(4\d{3}[ -]\d{4}[ -]\d{4}[ -]\d{4}\b|4\d{12}(?:\d{3})?)\b
Cette séquence indique au système de RegEx que nous cherchons un modèle comportant un nombre de 4 chiffres débutant par un 4, suivi d’un point et d’un deuxième nombre à 4 chiffres et… vous voyez l’idée. Seule une chaîne de caractères correspondant exactement à l’expression régulière générera un résultat positif.
Même s’il existe certaines similitudes entre les deux, la classification des données n’est pas synonyme d’indexation des données. La classification recherche des identifiants en fonction de modèles et renvoie une liste de fichiers ainsi que le nombre de correspondances trouvées pour chaque modèle. Elle n’effectue pas nécessairement une indexation de ces fichiers. L’indexation permet la recherche, et vous devrez chercher ces correspondances pour répondre aux demandes d’accès aux données personnelles et aux demandes de droit à l’oubli.
Les raisons de la classification des données

Le Center for Internet Security (CIS)- qui consacre une section entière aux protections en matière de classification des données – estime que la classification des données est importante car « dans plusieurs failles de sécurité majeures qui se sont produites au cours des deux dernières années, les pirates ont pu accéder à des données sensibles stockées sur les mêmes serveurs et avec le même niveau d’accès que pour des données bien moins importantes. »
Au-delà des questions de sécurité des données, il existe plusieurs autres raisons de mettre en œuvre un processus de classification des données :
- Identifier les fichiers sensibles, la propriété intellectuelle et les secrets commerciaux
- Sécuriser (et verrouiller) les données critiques
- Suivre les données réglementées afin de se conformer à des réglementations telles que HIPAA, PCI ou GDPR
- Optimiser les capacités de recherche grâce à l’indexation des données
- Découvrir des modèles ou des tendances statistiquement significatifs à l’intérieur des données
- Optimiser le stockage en identifiant les données dupliquées ou obsolètes
Processus de classification des données : 4 étapes
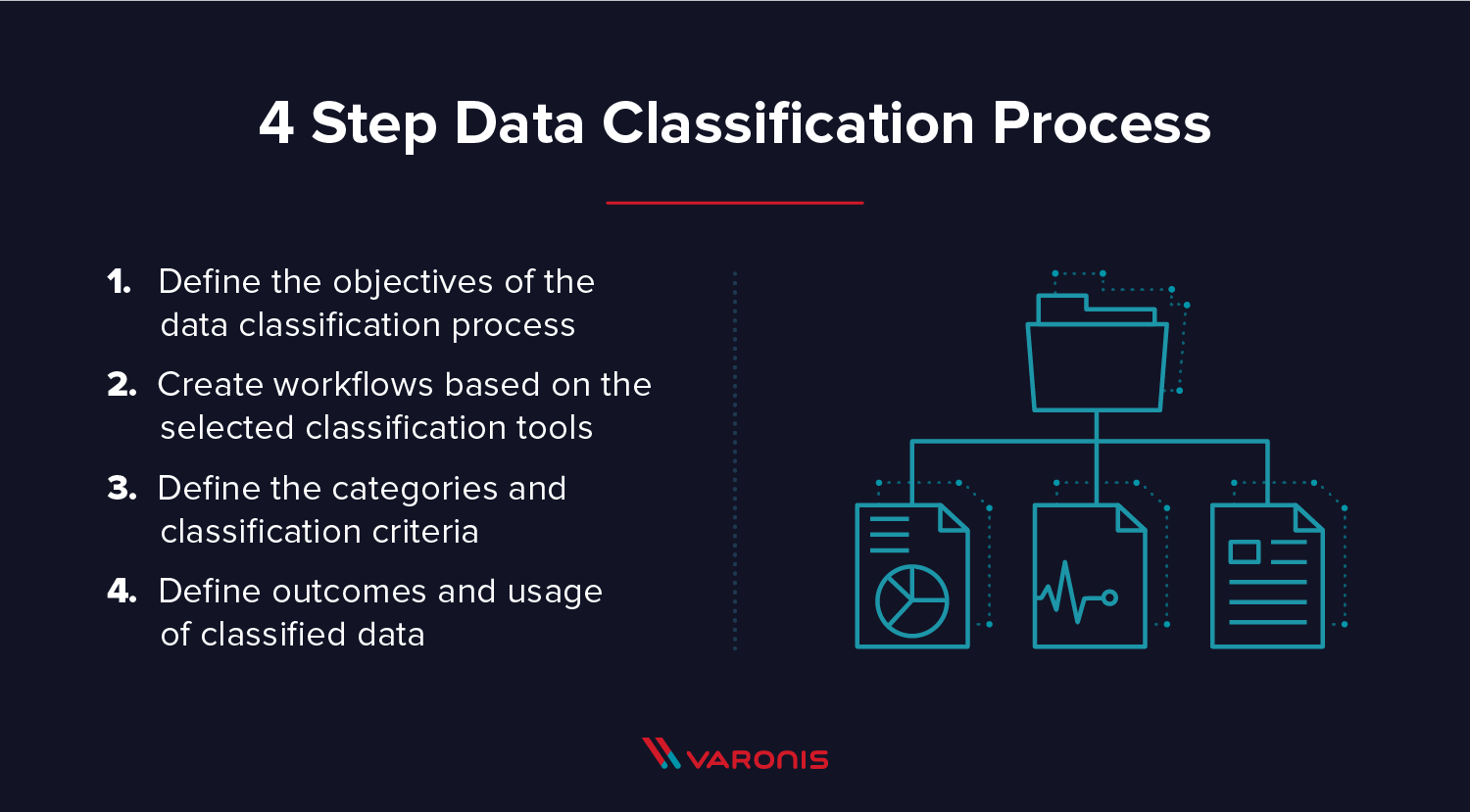
Les processus de classification des données diffèrent légèrement en fonction des objectifs du projet. Dans tout projet de ce type, l’automatisation est nécessaire pour traiter la formidable quantité de données générées chaque jour par les entreprises. En général, un processus de classification des données repose sur quelques critères universels :
- Définir les objectifs du processus. Que cherchez-vous ? Pourquoi ?
- Créer des workflows en fonction des outils de classification sélectionnés. Comment fonctionne le processus de classification ? Y a-t-il un processus en place pour analyser les nouvelles données ? Y a-t-il un processus pour créer de nouveaux critères de classification ?
- Définir les catégories et les critères de classification. Quels types de données recherchez-vous ? Quel processus suivrez-vous pour valider les résultats de la classification ?
- Définir les objectifs et l’utilisation des données classifiées. Comment les résultats sont-ils organisés, et comment prévoyez-vous de les exploiter pour prendre des décisions opérationnelles ?
Conseils pour la classification des données
- Utilisez des outils automatisés pour traiter rapidement de gros volumes de données.
- Exploitez les RegEx et formules de Luhn : créez des modèles de classification personnalisés ou utilisez des logiciels qui font le gros du travail pour vous.
- Validez vos résultats de classification : personne n’aime les faux positifs.
- Trouvez le moyen d’utiliser au mieux vos résultats et utilisez la classification dans tous les domaines, depuis la sécurité des données jusqu’à la business intelligence.
Classification des données : foire aux questions
En quoi la solution de classification des données de Varonis est-elle différente ?
Varonis propose plus de 400 expressions régulières préconfigurées pour découvrir tous les types de données PII, PHI et GDPR, avec un moteur de classification totalement personnalisable que vous pouvez configurer pour tous vos besoins professionnels. Varonis contrôle d’emblée plus de 60 types de fichiers (dont des documents, feuilles de calcul et plus encore), et identifie les nouvelles données nécessitant une nouvelle analyse (sans recommencer la totalité du processus), afin de détecter les fichiers sensibles nouveaux ou récemment modifiés, y compris :
- Les informations personnelles : numéros de carte de crédit, numéros de passeport, numéros de permis de conduire, numéros de sécurité sociale, IBAN et plus encore
- Les dossiers financiers
- Les types de fichier de sécurité (.cer, crt, p7b, etc.)
- Les données réglementées (GDPR, HIPAA, PII, PHI, PCI, Sarbanes Oxley, GLBA, etc.)
Le moteur de classification des données de Varonis (Data Classification Engine, on a fait simple) peut traiter environ 100 Go de données en une heure (en fonction des capacités de vos propres matériels et réseau) et intègre des contrôles rigoureux de faux positif qui réduisent la charge de travail nécessaire à l’analyse des résultats de la classification. Toutes les chaînes comportant 16 caractères numériques ne sont pas un numéro de carte de crédit et Varonis sait faire la différence.
Qu’est-ce qui vient après la classification des données ?
Varonis apporte un contexte à cette classification. Non seulement la solution de Varonis identifie les données que vous recherchez, mais elle vous montre qui peut accéder à ces données, et qui y accède. Une fois que vous avez identifié et classé les données sensibles, vous pouvez prendre des mesures à leur sujet : appliquer des étiquettes, verrouiller les permissions, surveiller les accès, émettre des alertes en cas d’activité suspecte, et vous conformer aux exigences en matières de conformité, telles que le droit à l’oubli. Varonis Data Classification Engine vous permet de protéger vos données les plus sensibles et les plus importantes contre les accès non désirés, les fuites de données et les attaques.
Découvrez comment fonctionne Varonis Data Classification Engine dans le cadre d’une démonstration individuelle.
What you should do now
Below are three ways we can help you begin your journey to reducing data risk at your company:
- Schedule a demo session with us, where we can show you around, answer your questions, and help you see if Varonis is right for you.
- Download our free report and learn the risks associated with SaaS data exposure.
- Share this blog post with someone you know who'd enjoy reading it. Share it with them via email, LinkedIn, Reddit, or Facebook.




-1.png)

