
S’il est bien un point très important mais sous-estimé lorsqu’il est question de conformité aux réglementations strictes en matière de données, comme c’est le cas avec le Règlement général sur la protection des données (GDPR), c’est la nécessité de trouver et classer les informations personnellement identifiables, ou données à caractère personnel, comme on les désigne dans l’UE. Découvrir où se trouvent les données à caractère personnel dans les systèmes de fichiers et déterminer les droits utilisés pour les protéger devrait être la première étape de tout plan d’action.
Nous ne vous demandons pas de nous croire sur parole, vous pouvez consulter les listes de tâches constituées par les cabinets juridiques et les groupes de conseil qui travaillent en collaboration étroite avec les sociétés de conseil dans le domaine de la conformité.
Nous vous avions déjà informés de l’existence des Patterns GDPR de Varonis, une solution qui aide à localiser ces données à caractère personnel, et maintenant que j’en ai appris encore plus auprès de Sarah et de l’équipe de développement produit de Varonis, j’ai d’autres choses à vous dire.
Personne ne fait mieux
GDPR Patterns est, bien entendu, basé sur notre Data Classification Framework ou DCF. Pour ceux qui ne connaissent pas Varonis, le DCF présente un gros avantage par rapport aux autres solutions de classification puisqu’il met en œuvre une véritable analyse incrémentale. Après une première analyse du système de fichiers, le DCF est en mesure d’identifier rapidement toute modification puis d’analyser de manière sélective les annuaires ou dossiers auxquels des utilisateurs ont accédé. Cette manière de procéder est bien plus pertinente que de réaliser une analyse complète.
D’ailleurs, les personnes assez folles pour envisager de développer elles-mêmes leur propre logiciel d’analyse de données sont invitées à lire ma série d’articles sur la création artisanale d’un système de classification basé sur PowerShell. Profitez de ma folle expérience, l’envie vous passera.
Le DCF faisant le gros du travail, GDPR Pattern peut se concentrer sur la localisation dans les fichiers, des données à caractères personnel telles que l’entend le GDPR. D’après la définition du GDPR, les données à caractère personnel sont en fait tout élément concernant un individu pouvant servir à l’identifier. La définition est très large et les termes utilisés suffisamment flous pour couvrir un champ très vaste ! (Pour connaître tous les détails, consultez le document officiel de l’UE.)
Bien évidemment, cela comprend toutes les informations classiques telles que noms, adresses, numéros de téléphone, numéros de carte de crédit, numéros de comptes bancaires et numéros de compte divers. Les données à caractère personnel couvertes par le GDPR comprennent aussi des identifiants Internet tels qu’adresses IP et adresses e-mail, ainsi que les identifiants biométriques futuristes tels que la reconnaissance rétinienne et de l’ADN.
Des identifiants européens très divers
L’UE étant constituée de 28 pays, de nombreuses données d’identification varient d’un pays à l’autre. C’est là que l’équipe de Varonis a réalisé un gros travail de recherche puisqu’elle a passé des mois à analyser les numéros de téléphone, numéros de plaque d’immatriculation, codes de TVA, passeports, permis de conduire et numéros d’identification personnels de toute l’UE.
Quelqu’un sait-il à quoi ressemble le « Születési szám », c’est-à-dire le numéro d’identification personnel utilisé en Hongrie ?
C’est en fait une séquence de 11 chiffres basée sur la date de naissance, le sexe, un numéro unique différenciant les personnes nées le même jour, et un total de contrôle.
Et le numéro de passeport utilisé en Slovaquie ?
Il est constitué de 9 caractères : 2 chiffres suivis de 7 lettres.
Varonis a tiré tout cela au clair !
Nous utilisons des expressions régulières, ou regex, pour établir des correspondances entre les modèles, lorsque c’est possible. Créer ces regex n’est pas aussi simple que l’on pourrait le croire.
Si vous voulez vous mesurer aux personnes qui ont mis au point le modèle de numéro de plaque d’immatriculation néerlandais, vous pouvez cliquer ici pour voir l’analyse regex d’un exemple de numéro. Ensuite, vous pouvez essayer avec d’autres numéros pour voir si vous avez compris. Amusez-vous bien !
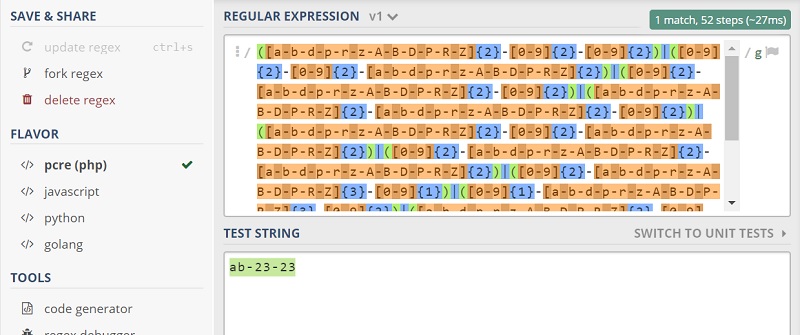
Modèles : plus que des regex
Les recherches et efforts que nous avons consacrés aux expressions régulières ne sont qu’un aspect de GDPR Patterns. Bien sûr, on peut imaginer qu’une personne mette au point des regex pour quelques pays ou fasse des recherches sur Google pour trouver ces expressions sur le Web.
De notre côté, nous avons conçu nos regex en examinant des échantillons de données réels, et pas seulement en acceptant automatiquement les informations fournies par les agences de l’État et autres. Nos regex GDPR ont fait leurs preuves sur le terrain !
Face à la multitude de modèles alphanumériques différents, il ne serait guère surprenant que des « collisions » se produisent parfois, c’est-à-dire que des séquences soient classées dans plusieurs types de données personnelles. Par exemple, les numéros de passeport européens contiennent entre 8 et 10 chiffres consécutifs et pourraient donc facilement être détectés par un regex de numéro de téléphone européen.
C’est la raison pour laquelle nous avons complétés nos regex d’algorithmes de validation. Plus précisément, GDPR Patterns lance une analyse pour rechercher des mots clés particuliers à proximité des données à caractère personnel utilisées en UE : si nous trouvons le mot clé, cela nous aide à identifier le modèle GDPR adéquat.
À titre d’exemple, lorsque GDPR Patterns trouve un nombre à 11 chiffres, il recherche des mots clés supplémentaires pour déterminer s’il correspond à un numéro d’identification national : « IK » ou « ISIKUKOOD » correspond à l’Estonie ; « Születési szám », « Személyi szám » ou « Személyi azonosító » correspondrait bien sûr à la Hongrie, etc.
Si nous ne trouvons pas de mots clés supplémentaires, nous ne pouvons pas considérer que les 11 chiffres correspondent à un code d’identification, et le numéro n’est pas classé en tant que donnée à caractère personnel soumise au GDPR. Autrement dit, les algorithmes de validation réduisent les faux positifs.
Au cas où vous poseriez la question, nous utilisons aussi des mots clés négatifs. Si GDPR Patterns trouve un de ces types de mots clés, cela signifie que la donnée personnelle identifiée par l’expression regex ne peut pas être classée dans ce modèle.
Informations complémentaires sur GDPR Patterns
Les développeurs de Varonis ont étudié des échantillons réels de numéros pour procéder à un examen détaillé des numéros d’identification, de permis de conduire, de plaque d’immatriculation et de téléphone en vigueur en UE, et identifier des mots clés positifs et négatifs ainsi que des informations de proximité.
Nous avons intégré GDPR Patterns à nos rapports DatAdvantage pour montrer quels fichiers contiennent un certain modèle en fonction du nombre d’occurrences.
De la même façon, GDPR Patterns est aussi intégré à DatAlert afin que les alertes puissent être émises en cas d’accès à des fichiers contenant des données à caractère personnel. Nous vous aiderons à signaler les fuites de données sous 72 heures, comme l’exige le GDPR.
Data Transport Engine utilisera lui aussi GDPR Patterns pour archiver ou supprimer les données à caractère personnel devenues obsolètes ou qui ne sont plus utilisées, une autre exigence du GDPR.
Vous avez des questions ? Contactez-nous pour obtenir plus d’informations.
What you should do now
Below are three ways we can help you begin your journey to reducing data risk at your company:
- Schedule a demo session with us, where we can show you around, answer your questions, and help you see if Varonis is right for you.
- Download our free report and learn the risks associated with SaaS data exposure.
- Share this blog post with someone you know who'd enjoy reading it. Share it with them via email, LinkedIn, Reddit, or Facebook.




-1.png)

