Un des (nombreux) aspects déconcertants du Règlement général sur la protection des données (GDPR) de l’UE est le « droit à l’oubli ». Il est lié au droit à l’effacement, mais couvre un terrain bien plus large. Le droit d’exiger la suppression de nos informations personnelles signifie que les données conservées par le responsable du traitement des données doivent être supprimées sur demande du client. Le droit à l’oubli concerne plus spécifiquement les données personnelles que le responsable du traitement a rendues publiques sur Internet.
Simple, n’est-ce pas ?
Pas tant que cela, selon les cas.
Je suis tombé sur un article sur ce sujet, qui examine en détail les questions juridiques et techniques liées à l’effacement et à l’« oubli ». Les auteurs indiquent que la notion de suppression n’a pas le même sens selon que l’on parle du big data et de l’intelligence artificielle, ou de données conservées sur un système de fichiers.
Cet article contient des informations importantes sur l’histoire récente du droit à l’oubli. Prenez le temps de le lire, cela en vaut la peine.


Court résumé d’un résumé
En 2010, un certain M. Costeja González a déposé auprès de l’Autorité espagnole de protection des données (DPA) une plainte visant Google et un journal espagnol. Il s’est rendu compte que lorsqu’il saisissait son nom dans Google, les résultats de recherche affichaient un lien menant à un article de journal qui signalait la vente d’un bien par M. González au motif de solder des dettes personnelles.
L’Autorité espagnole de protection des données a rejeté la plainte visant le journal puisque celui-ci avait l’obligation légale de publier la vente du bien. La DPA a toutefois maintenu la plainte contre Google.
L’argument de Google était que puisque la société n’avait aucune présence réelle en Espagne (aucun serveur physique situé en Espagne ne contenait les données) et que les données étaient traitées en dehors de l’UE, elles n’étaient pas soumises à la Directive sur la protection des données (DPD) de l’UE.
Au final, la Cour de Justice, la plus haute instance judiciaire, a déclaré dans sa décision de 2014 concernant le droit à l’oubli que : les entreprises de moteur de recherche sont considérées comme étant des responsables du traitement des données ; la DPD s’applique aux entreprises qui vendent leurs services en UE (qu’elles y soient présentes physiquement ou non) ; et les clients ont le droit de demander aux entreprises de moteur de recherche la suppression de liens menant à des informations personnelles les concernant.
Le GDPR deviendra une loi européenne et remplacera la DPD en mai 2018 : l’article 17 aborde le droit à l’oubli, et l’Article 3 précise la portée extra-territoriale de la décision.
Toutefois, ce qui est intéressant dans ce cas, c’est que les informations d’origine sur M. Gonzalez n’ont jamais été supprimées et qu’elles sont toujours accessibles en lançant une recherche dans la version en ligne du journal.
En pratique, l’« oubli » consiste donc à supprimer une clé ou un lien menant aux informations personnelles, mais pas les données elles-mêmes.
Ne perdez pas ceci de vue.
L’intelligence artificielle est comme un mini-Google
La seconde partie de l’article explique très bien le b.a.-ba de ce qui se passe lorsque des données sont supprimées dans un logiciel. Ces informations sont très instructives pour les personnes sans connaissances techniques.
Les techniciens, quant à eux, savent que lorsque l’on en a terminé avec un objet de données dans une appli et que l’on efface ou « libère » la mémoire, les données ne disparaissent pas comme par enchantement. Au lieu de cela, le morceau de mémoire est placé sur une « liste liée » qui est traitée tôt ou tard et insérée dans une mémoire logicielle disponible en vue d’une réutilisation éventuelle.
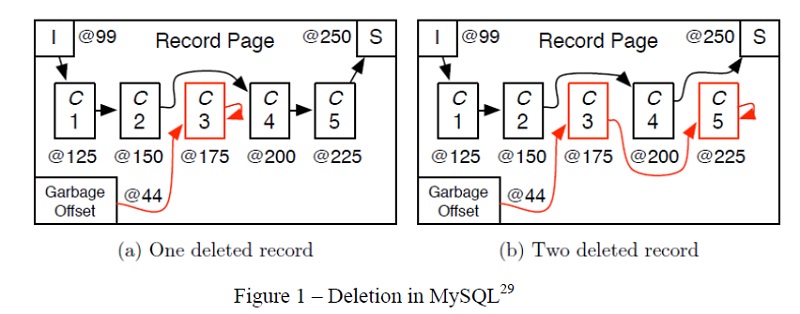
Appelée « nettoyage de la mémoire » ou « ramasse-miettes », cette procédure permet aux logiciels exigeants de retarder la mise au rebut des données, un processus qui utilise l’UC de manière intensive, à un moment où l’appli n’est pas occupée.
L’apprentissage automatique utilise de vastes ensembles de données pour entraîner le logiciel et en déduire des règles de prise de décision. Le logiciel affecte et supprime en permanence des données, souvent personnelles, qui peuvent à un moment donné être placées dans une file d’attente afin d’être mises au rebut.
Que signifie alors mettre en œuvre le droit à l’oubli dans une appli d’intelligence artificielle ou de big data ?
Les auteurs de l’article font remarquer qu’il est peu probable que la suppression d’un point de données unique affecte les règles du logiciel d’intelligence artificielle. Très bien. Mais assurément, si des dizaines ou des centaines de milliers de personnes font jouer leur droit à l’effacement dans le cadre du GDPR, on peut s’attendre à ce que ces règles évoluent.
Ils indiquent également que ces données peuvent être déguisées en utilisant des techniques d’anonymisation ou de pseudonymisation pour éviter de stocker des données identifiables et contourner ainsi le droit à l’oubli. Certaines de ces techniques d’anonymisation impliquent d’ajouter des « parasites » qui peuvent parfois affecter l’exactitude des règles.
Ceci nous mène à une approche de mise en œuvre du droit à l’oubli dans le cas de l’intelligence artificielle auquel nous avons fait allusion plus haut : l’oubli passe peut-être par le fait d’empêcher l’accès aux données d’origine !
C’est ce que fait le processus de ramasse-miettes en plaçant la mémoire dans une file d’attente séparée qui la rend inaccessible au reste du logiciel – le « handle » entre le logiciel et la mémoire n’autorise plus d’accès. Google fait la même chose en retirant l’URL du site Web de son index interne.
Dans les deux cas, les données sont toujours là mais elles sont, dans les faits indisponibles.
La clé mémoire
Dans le domaine de l’intelligence artificielle, l’oubli repose sur l’idée de supprimer ou effacer la clé qui permet d’accéder aux données.
L’article s’achève en suggérant que nous devrons explorer des moyens plus pratiques (et économiques) de gérer le droit à l’oubli pour les applis de big data.
Perdre la clé est une piste possible. D’autres méthodes sont envisageables, comme de fragmenter les données personnelles en ensembles de plus petite taille (ou de les mettre en silo) afin qu’il soit impossible ou extrêmement difficile de réidentifier chaque ensemble séparé.
Il est évident que supprimer des données personnelles d’un système de fichiers n’est pas forcément simple, mais c’est une difficulté que l’on peut surmonter sans problème lorsque l’on dispose des bons outils !
C’est un fait entendu, dans le domaine de l’intelligence artificielle, l’oubli est plus complexe à mettre en œuvre et exige de trouver des solutions autres que la suppression des fichiers. Il est possible que nous voyions aussi apparaître de nouvelles technologies similaires à l’effacement dans le domaine de l’intelligence artificielle.
D’ici là, il est probable que les régulateurs européens ne manqueront pas de nous faire part de leur vision du droit à l’oubli dans le cas des applications de big data. Nous vous tiendrons au courant !
What you should do now
Below are three ways we can help you begin your journey to reducing data risk at your company:
- Schedule a demo session with us, where we can show you around, answer your questions, and help you see if Varonis is right for you.
- Download our free report and learn the risks associated with SaaS data exposure.
- Share this blog post with someone you know who'd enjoy reading it. Share it with them via email, LinkedIn, Reddit, or Facebook.